This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Everyone talks about dataquality, as they should. Our research shows that improving the quality of information is the top benefit of data preparation activities. Dataquality efforts are focused on clean data. Yes, clean data is important. but so is bad data.
data engineers delivered over 100 lines of code and 1.5 dataquality tests every day to support a cast of analysts and customers. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states. We are excited to talk about how to use dynamic rules , a new capability of AWS Glue DataQuality.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
In recent years, datalakes have become a mainstream architecture, and dataquality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex dataquality rulesets over a predefined test dataset.
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, dataquality and master data management.
Under that focus, Informatica's conference emphasized capabilities across six areas (all strong areas for Informatica): data integration, data management, dataquality & governance, Master Data Management (MDM), data cataloging, and data security.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
Ensuring that data is available, secure, correct, and fit for purpose is neither simple nor cheap. Companies end up paying outside consultants enormous fees while still having to suffer the effects of poor dataquality and lengthy cycle time. . For example, DataOps can be used to automate data integration.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
Making your datalake a “governed datalake” is the game changer. Without governance, organizations risk securing the data and as well as protecting it. A governed datalake contains data that’s accessible, clean, trusted and protected.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. Hundreds of thousands of customers use datalakes for analytics and ML to make data-driven business decisions.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
We pulled these people together, and defined use cases we could all agree were the best to demonstrate our new data capability. Once they were identified, we had to determine we had the right data. Then we migrated the data to our new datalake, and stood up the new platform.
On the agribusiness side we source, purchase, and process agricultural commodities and offer a diverse portfolio of products including grains, soybean meal, blended feed ingredients, and top-quality oils for the food industry to add value to the commodities our customers desire. The data can also help us enrich our commodity products.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. The data science and AI teams are able to explore and use new data sources as they become available through Amazon DataZone.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
In order to help maintain data privacy while validating and standardizing data for use, the IDMC platform offers a DataQuality Accelerator for Crisis Response. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
“All of a sudden, you’re trying to give this data to somebody who’s not a data person,” he says, “and it’s really easy for them to draw erroneous or misleading insights from that data.” As more companies use the cloud and cloud-native development, normalizing data has become more complicated.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional datalake structures by offering an advanced combination of flexibility, performance, and governance capabilities. For more information, refer to What are deletion vectors?
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. Both operations target the same partition based on customer_id , leading to potential conflicts because theyre modifying an overlapping dataset.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
It’s stored in corporate data warehouses, datalakes, and a myriad of other locations – and while some of it is put to good use, it’s estimated that around 73% of this data remains unexplored. Improving dataquality. Unexamined and unused data is often of poor quality. Data augmentation.
To provide a response that includes the enterprise context, each user prompt needs to be augmented with a combination of insights from structured data from the data warehouse and unstructured data from the enterprise datalake. Implement data privacy policies. Implement dataquality by data type and source.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. Dataquality check – The dataquality module enables you to perform quality checks on a huge amount of data and generate reports that describe and validate the dataquality.
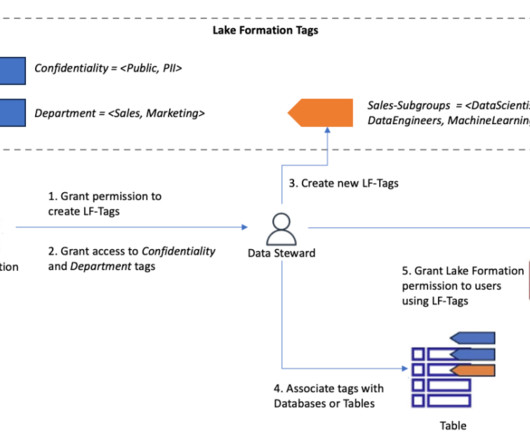
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a data governance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. In 2022 , we talked about the enhancements we had done to these services. Bien intégré!
As organizations process vast amounts of data, maintaining an accurate historical record is crucial. History management in data systems is fundamental for compliance, business intelligence, dataquality, and time-based analysis. Hes passionate about helping customers use Apache Iceberg for their datalakes on AWS.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content