This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here, CIO Patrick Piccininno provides a roadmap of his journey from data with no integration to meaningful dashboards, insights, and a data literate culture. You ’re building an enterprisedata platform for the first time in Sevita’s history. Second, the manual spreadsheet work resulted in significant manual data entry.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
The data mesh design pattern breaks giant, monolithic enterprisedata architectures into subsystems or domains, each managed by a dedicated team. But first, let’s define the data mesh design pattern. The past decades of enterprisedata platform architectures can be summarized in 69 words.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. . The challenge is that data engineering and analytics are incredibly complex. Ensuring that data is available, secure, correct, and fit for purpose is neither simple nor cheap.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
The sheer scale of data being captured by the modern enterprise has necessitated a monumental shift in how that data is stored. What was at first a data stream has morphed into a data river as enterprise businesses are harvesting reams of data from every conceivable input across every conceivable business function.
We can use foundation models to quickly perform tasks with limited annotated data and minimal effort; in some cases, we need only to describe the task at hand to coax the model into solving it. But these powerful technologies also introduce new risks and challenges for enterprises.
Between building gen AI features into almost every enterprise tool it offers, adding the most popular gen AI developer tool to GitHub — GitHub Copilot is already bigger than GitHub when Microsoft bought it — and running the cloud powering OpenAI, Microsoft has taken a commanding lead in enterprise gen AI.
Applying artificial intelligence (AI) to data analytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
Just after launching a focused data management platform for retail customers in March, enterprisedata management vendor Informatica has now released two more industry-specific versions of its Intelligent Data Management Cloud (IDMC) — one for financial services, and the other for health and life sciences.
On the agribusiness side we source, purchase, and process agricultural commodities and offer a diverse portfolio of products including grains, soybean meal, blended feed ingredients, and top-quality oils for the food industry to add value to the commodities our customers desire. The data can also help us enrich our commodity products.
Starting on a solid data foundation Before choosing a platform for sharing data, an organization needs to understand what data it already has and strip it of errors and duplicates. Data formats and data architectures are often inconsistent, and data might even be incomplete. They have data swamps,” he says.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
For the past 5 years, BMS has used a custom framework called EnterpriseDataLake Services (EDLS) to create ETL jobs for business users. Dataquality check – The dataquality module enables you to perform quality checks on a huge amount of data and generate reports that describe and validate the dataquality.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Q: Is data modeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. The continued federation of data in the enterprise resulted in data silos.
It’s stored in corporate data warehouses, datalakes, and a myriad of other locations – and while some of it is put to good use, it’s estimated that around 73% of this data remains unexplored. Improving dataquality. Unexamined and unused data is often of poor quality. Data augmentation.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
Lastly, active data governance simplifies stewardship tasks of all kinds. Tehnical stewards have the tools to monitor dataquality, access, and access control. A compliance steward is empowered to monitor sensitive data and usage sharing policies at scale. The Data Swamp Problem. The Governance Solution.
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. With automation, dataquality is systemically assured.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
And Doug Shannon, automation and AI practitioner, and Gartner peer community ambassador, says the vast majority of enterprises are now focused on two categories of use cases that are most likely to deliver positive ROI. Classifiers are provided in the toolkits to allow enterprises to set thresholds. “We
Gartner calls it the Composable Enterprise , for example – it’s about having a solid information foundation that enables fast and flexible creation of what they call composable applications that allow you to create new applications and workflows by just bringing together modular components. Business Process. Business Context.
Analytics reference architecture for gaming organizations In this section, we discuss how gaming organizations can use a data hub architecture to address the analytical needs of an enterprise, which requires the same data at multiple levels of granularity and different formats, and is standardized for faster consumption.
Implementing the right data strategy spurs innovation and outstanding business outcomes by recognizing data as a critical asset that provides insights for better and more informed decision-making. By taking advantage of data, enterprises can shape business decisions, minimize risk for stakeholders, and gain competitive advantage.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI).
These stewards monitor the input and output of data integrations and workflows to ensure dataquality. Their focus is on master data management , datalakes / warehouses, and ensuring the trackability of data using audit trails and metadata. How to Get Started with Information Stewardship.
Making the most of enterprisedata is a top concern for IT leaders today. With organizations seeking to become more data-driven with business decisions, IT leaders must devise data strategies gear toward creating value from data no matter where — or in what form — it resides. Quality is job one.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. From establishing an enterprise-wide data inventory and improving data discoverability, to enabling decentralized data sharing and governance, Amazon DataZone has been a game changer for HEMA.
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. Testing will eliminate lots of dataquality challenges and bring a test-first approach through your agile cycle.
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Towards Data Science ). Forrester ).
It allows users to write data transformation code, run it, and test the output, all within the framework it provides. Use case The EnterpriseData Analytics group of a large jewelry retailer embarked on their cloud journey with AWS in 2021. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake.
Birgit Fridrich, who joined Allianz as sustainability manager responsible for ESG reporting in late 2022, spends many hours validating data in the company’s Microsoft Sustainability Manager tool. Dataquality is key, but if we’re doing it manually there’s the potential for mistakes.
Selling the value of data transformation Iyengar and his team are 18 months into a three- to five-year journey that started by building out the data layer — corralling data sources such as ERP, CRM, and legacy databases into data warehouses for structured data and datalakes for unstructured data.
Many enterprises are migrating their on-premises data stores to the AWS Cloud. During data migration, a key requirement is to validate all the data that has been moved from source to target. This data validation is a critical step, and if not done correctly, may result in the failure of the entire project.
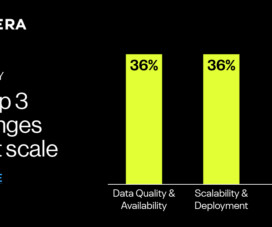
Among the most common challenges to achieving AI adoption at scale were dataquality and availability (36%), scalability and deployment (36%), integration with existing systems and processes (35%), and change management and organizational culture (34%).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content