This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. We show two example scripts demonstrating a practical implementation of error handling for data conflicts in Iceberg streaming jobs.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
Unstructured data is typically stored across siloed systems in varying formats, and generally not managed or governed with the same level of rigor as structured data. On the backend, the batch data engineering processes refreshing the enterprise datalake need to expand to ingest, transform, and manage unstructured data.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. Finally, to interact with and visualize results from our solution, we build an interactive Streamlit web application running on AWS Fargate.
17 software developers met to discuss lightweight development methods and subsequently produced the following manifesto : Manifesto for Agile Software Development: Individuals and interactions over processes and tools. Testing will eliminate lots of dataquality challenges and bring a test-first approach through your agile cycle.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
This is just the tip of the iceberg, because what enables you to obtain differential value from generative AI is your data. This data is derived from your purpose-built data stores and previous interactions. Semantic context – Is there any meaningfully relevant data that would help the FMs generate the response?
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. Then, you transform this data into a concise format.
In Foundry’s 2022 Data & Analytics Study , 88% of IT decision-makers agree that data collection and analysis have the potential to fundamentally change their business models over the next three years. The ability to pivot quickly to address rapidly changing customer or market demands is driving the need for real-time data.
Griffin is an open source dataquality solution for big data, which supports both batch and streaming mode. In today’s data-driven landscape, where organizations deal with petabytes of data, the need for automated data validation frameworks has become increasingly critical.
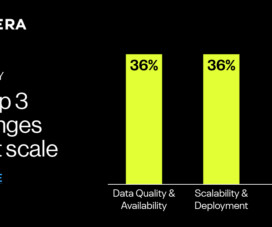
Among the most common challenges to achieving AI adoption at scale were dataquality and availability (36%), scalability and deployment (36%), integration with existing systems and processes (35%), and change management and organizational culture (34%).
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies. But, What Happened to Hadoop?
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI).
How do data and digital technologies impact your business strategy? At the core, digital at Dow is about changing how we work, which includes how we interact with systems, data, and each other to be more productive and to grow. Data is at the heart of everything we do today, from AI to machine learning or generative AI.
“The insights derived from this audio data have directly contributed to improving the game’s audio experience, ensuring that players are constantly emotionally engaged in the gameplay and interacting with the environment,” Konoval says. Games are dynamic, and so is the data they generate, Konoval says. Quality is job one.
As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform. Data sources As part of this data platform, we are ingesting data from diverse and varied data sources, including: Transactional databases – These are active databases that store real-time data from various applications.
This plane drives users to engage in data-driven conversations with knowledge and insights shared across the organization. Through the product experience plane, data product owners can use automated workflows to capture data lineage and dataquality metrics and oversee access controls.
“The number-one issue for our BI team is convincing people that business intelligence will help to make true data-driven decisions,” says Diana Stout, senior business analyst at Schellman, a global cybersecurity assessor based in Tampa, Fl. But what they really need to do is fundamentally rethink how data is managed and accessed,” he says.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Improved Decision Making : Well-modeled data provides insights that drive informed decision-making across various business domains, resulting in enhanced strategic planning. Reduced Data Redundancy : By eliminating data duplication, it optimizes storage and enhances dataquality, reducing errors and discrepancies.
Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data. Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program.
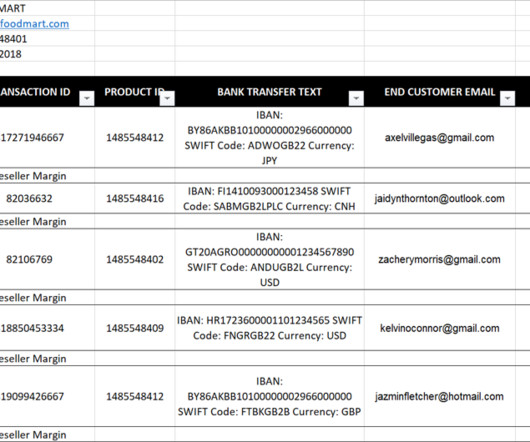
As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. DataBrew is an excellent tool for dataquality and preprocessing. Select the FoodMartSales-AllUp dataset.
It proposes a technological, architectural, and organizational approach to solving data management problems by breaking up the monolithic data platform and de-centralizing data management across different domain teams and services. Once these domains interact and share data with each other, the mesh emerges.
“At Databricks, we’re focused on enabling customers to adopt the data lakehouse, and that’s an open data architecture that combines the best of the data warehouse and the datalake into one platform,” Ferguson says. “[The And data governance is critical to driving adoption.”.
With AWS Glue, you can discover and connect to hundreds of different data sources and manage your data in a centralized data catalog. You can visually create, run, and monitor ETL pipelines to load data into your datalakes.
Equally crucial is the ability to segregate and audit problematic data, not just for maintaining data integrity, but also for regulatory compliance, error analysis, and potential data recovery. One of its key features is the ability to manage data using branches. It specifies which data is clean and ready to be provided.
Data mesh solves this by promoting data autonomy, allowing users to make decisions about domains without a centralized gatekeeper. It also improves development velocity with better data governance and access with improved dataquality aligned with business needs.
“Alation’s modern, web-based, user-friendly interfaces provide a good set of workflows and functions to interact with the system intuitively,” the report reads. Alation’s usability goes well beyond data discovery (used by 81 percent of our customers), data governance (74 percent), and data stewardship / dataquality management (74 percent).
Dataquality strongly impacts the quality and usefulness of content produced by an AI model, underscoring the significance of addressing data challenges. Summarization can help employees by providing them a brief of the customer’s problem and previous interactions with the company.
What Are the Top Data Challenges to Analytics? The proliferation of data sources means there is an increase in data volume that must be analyzed. Large volumes of data have led to the development of datalakes , data warehouses, and data management systems. Establishes Trust in Data.
Therefore, it’s crucial to keep the schema definition in the Schema Registry and the Data Catalog table in sync. To avoid this, it’s recommended to use a dataquality check mechanism to identify such anomalies and take appropriate action in case of unexpected behavior. The following diagram illustrates our solution architecture.
However, often the biggest stumbling block is a human one, getting people to buy in to the idea that the care and attention they pay to data capture will pay dividends later in the process. These and other areas are covered in greater detail in an older article, Using BI to drive improvements in dataquality.
Showpad built new customer-facing embedded dashboards within Showpad eOSTM and migrated its legacy dashboards to Amazon QuickSight , a unified BI service providing modern interactive dashboards, natural language querying, paginated reports, machine learning (ML) insights, and embedded analytics at scale.
Graphs reconcile such data continuously crawled from diverse sources to support interactive queries and provide a graphic representation or model of the elements within supply chain, aiding in pathfinding and the ability to semantically enrich complex machine learning (ML) algorithms and decision making.
Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? You cannot get away from a formalized delivery capability focused on regular, scheduled, structured and reasonably governed data. Datalakes don’t offer this nor should they. E.g. DataLakes in Azure – as SaaS.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content