This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. This innovation drives an important change: you’ll no longer have to copy or move data between datalake and data warehouses.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states. We are excited to talk about how to use dynamic rules , a new capability of AWS Glue DataQuality.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machinelearning.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, dataquality and master data management.
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machinelearning (ML), and application development. Hundreds of thousands of customers use datalakes for analytics and ML to make data-driven business decisions.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
The new, industry-targeted data management platforms — Intelligent Data Management Cloud for Health and Life Sciences and the Intelligent Data Management Cloud for Financial Services — were announced at the company’s Informatica World conference Tuesday. Intelligent Data Management Cloud for Health and Life Sciences.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
It’s stored in corporate data warehouses, datalakes, and a myriad of other locations – and while some of it is put to good use, it’s estimated that around 73% of this data remains unexplored. Improving dataquality. Unexamined and unused data is often of poor quality. Data augmentation.
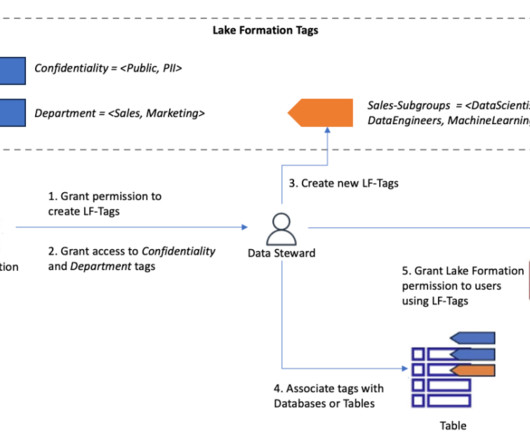
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
The need for an end-to-end strategy for data management and data governance at every step of the journey—from ingesting, storing, and querying data to analyzing, visualizing, and running artificial intelligence (AI) and machinelearning (ML) models—continues to be of paramount importance for enterprises.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. Dataquality check – The dataquality module enables you to perform quality checks on a huge amount of data and generate reports that describe and validate the dataquality.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. In this example, we searched for columns in our datalake that have similar Column Names ( payload type ) to district ( payload ).
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
Software development, once solely the domain of human programmers, is now increasingly the by-product of data being carefully selected, ingested, and analysed by machinelearning (ML) systems in a recurrent cycle. Further, data management activities don’t end once the AI model has been developed. era is upon us.
Solution To address the challenge, ATPCO sought inspiration from a modern data mesh architecture. ATPCO has existing datalake resources set up in multiple accounts, each owned by different data-producing teams. Enter a name, such as Sales – Datalake blueprint. Choose Accept & configure association.
ChatGPT> DataOps is a term that refers to the set of practices and tools that organizations use to improve the quality and speed of data analytics and machinelearning. Overall, DataOps is an essential component of modern data-driven organizations. Query> Write an essay on DataOps.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
My vision is that I can give the keys to my businesses to manage their data and run their data on their own, as opposed to the Data & Tech team being at the center and helping them out,” says Iyengar, director of Data & Tech at Straumann Group North America. The offensive side? The company’s Findability.ai
Many CIOs argue the rise of big data pushed people to use data more proactively for business decision-making. Big data got“ more leaders and people in the organization to use data, analytics, and machinelearning in their decision making,” says former CIO Isaac Sacolick. Big data can grow too big fast.
You can store that data in relational databases like Amazon Aurora , NoSQL databases, or graph databases like Amazon Neptune. The semantic context originates from vector data stores or machinelearning (ML) search services. The application gets prompt templates from an S3 datalake and creates the engineered prompt.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Start small with AI. Just starting out with analytics?
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Towards Data Science ). Forrester ).
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. A data hub contains data at multiple levels of granularity and is often not integrated.
At the core, digital at Dow is about changing how we work, which includes how we interact with systems, data, and each other to be more productive and to grow. Data is at the heart of everything we do today, from AI to machinelearning or generative AI. That’s what we’re running our AI and our machinelearning against.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and datalakes, aiming to support AI, BI, ML, and data engineering on a single platform.” According to Gartner, Inc.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make data integration effortless.
With each game release and update, the amount of unstructured data being processed grows exponentially, Konoval says. This volume of data poses serious challenges in terms of storage and efficient processing,” he says. To address this problem RetroStyle Games invested in datalakes. Quality is job one.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machinelearning (ML) and artificial intelligence (AI).
In Foundry’s 2022 Data & Analytics Study , 88% of IT decision-makers agree that data collection and analysis have the potential to fundamentally change their business models over the next three years. The ability to pivot quickly to address rapidly changing customer or market demands is driving the need for real-time data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content