This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. However, commits can still fail if the latest metadata is updated after the base metadata version is established.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional datalake structures by offering an advanced combination of flexibility, performance, and governance capabilities. These are useful for flexible data lifecycle management.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
In order to help maintain data privacy while validating and standardizing data for use, the IDMC platform offers a DataQuality Accelerator for Crisis Response. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a data governance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. In 2022 , we talked about the enhancements we had done to these services. Bien intégré!
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. EDLS job steps and metadata Every EDLS job comprises one or more job steps chained together and run in a predefined order orchestrated by the custom ETL framework.
To provide a response that includes the enterprise context, each user prompt needs to be augmented with a combination of insights from structured data from the data warehouse and unstructured data from the enterprise datalake. Implement data privacy policies. Implement dataquality by data type and source.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Solution To address the challenge, ATPCO sought inspiration from a modern data mesh architecture. Amazon DataZone provides rich functionality to help a data platform team distribute ownership of tasks so that these teams can choose to operate less like gatekeepers. Choose the Amazon DataZone blueprint you want to enable.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Your organization won’t be able to take complete advantage of analytics tools to become data-driven unless you establish a foundation for agile and complete data management. You need automated data mapping and cataloging through the integration lifecycle process, inclusive of data at rest and data in motion.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Monitoring Job Metadata. Adding Tests to Reduce Stress.
As organizations process vast amounts of data, maintaining an accurate historical record is crucial. History management in data systems is fundamental for compliance, business intelligence, dataquality, and time-based analysis. Hes passionate about helping customers use Apache Iceberg for their datalakes on AWS.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. DataBrew is an excellent tool for dataquality and preprocessing. For Matching conditions , choose Match all conditions.
These stewards monitor the input and output of data integrations and workflows to ensure dataquality. Their focus is on master data management , datalakes / warehouses, and ensuring the trackability of data using audit trails and metadata. How to Get Started with Information Stewardship.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
For state and local agencies, data silos create compounding problems: Inaccessible or hard-to-access data creates barriers to data-driven decision making. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Forrester ).
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data. Then, you transform this data into a concise format.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Dataquality using table rollback.
Solution overview OneData defines three personas: Publisher – This role includes the organizational and management team of systems that serve as data sources. Responsibilities include: Load raw data from the data source system at the appropriate frequency. Provide and keep up to date with technical metadata for loaded data.
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale.
Why do we need a data catalog? What does a data catalog do? These are all good questions and a logical place to start your data cataloging journey. Data catalogs have become the standard for metadata management in the age of big data and self-service analytics. Figure 1 – Data Catalog Metadata Subjects.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and datalakes, aiming to support AI, BI, ML, and data engineering on a single platform.” Iceberg handles massive data born in the cloud.
Jim Hare, distinguished VP and analyst at Gartner, says that some people think they need to take all the data siloed in systems in various business units and dump it into a datalake. But what they really need to do is fundamentally rethink how data is managed and accessed,” he says.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. The business end-users were given a tool to discover data assets produced within the mesh and seamlessly self-serve on their data sharing needs.
Bad data tax is rampant in most organizations. Currently, every organization is blindly chasing the GenAI race, often forgetting that dataquality and semantics is one of the fundamentals to achieving AI success. Sadly, dataquality is losing to data quantity, resulting in “ Infobesity ”. “Any
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























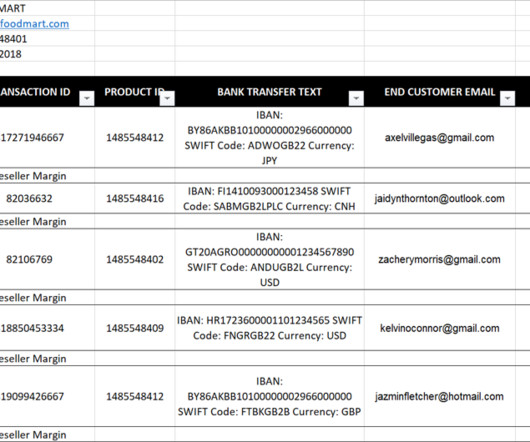
























Let's personalize your content