This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. This saves time and effort, especially for teams looking to minimize infrastructure management and focus solely on datamodeling.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. When combined with well-timed maintenance operations, these patterns help build resilient data pipelines that can handle concurrent writes reliably.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
Poor-qualitydata can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue DataQuality measures and monitors the quality of your dataset. It supports both dataquality at rest and dataquality in AWS Glue extract, transform, and load (ETL) pipelines.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
Data must be laboriously collected, curated, and labeled with task-specific annotations to train AI models. Building a model requires specialized, hard-to-find skills — and each new task requires repeating the process. ” These large models have lowered the cost and labor involved in automation.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Many organisations focus too heavily on fine tuning their computational models in their pursuit of ‘quick-wins.’
Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. In the traditional model communication between developers and business users is not a priority. This is also known as model storming, one of the practices in agile analytics development.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The workflow begins with an AWS Glue job that converts the CSV files into Apache Parquet data format.
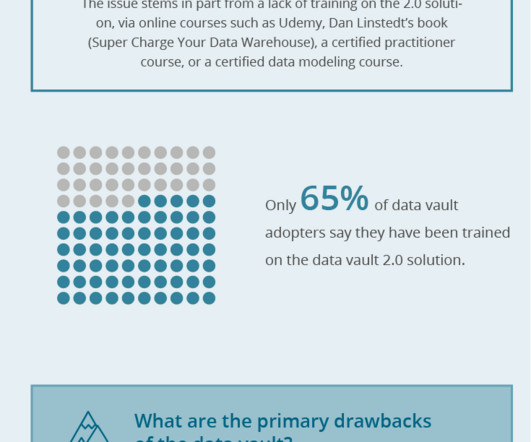
While most continue to struggle with dataquality issues and cumbersome manual processes, best-in-class companies are making improvements with commercial automation tools. The data vault has strong adherents among best-in-class companies, even though its usage lags the alternative approaches of third-normal-form and star schema.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. With automation, dataquality is systemically assured.
Privacy protection The first step in AI and gen AI projects is always to get the right data. “In In cases where privacy is essential, we try to anonymize as much as possible and then move on to training the model,” says University of Florence technologist Vincenzo Laveglia. “A A balance between privacy and utility is needed.
According to Kari Briski, VP of AI models, software, and services at Nvidia, successfully implementing gen AI hinges on effective data management and evaluating how different models work together to serve a specific use case. But some IT leaders are getting it right because they focus on three key aspects.
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
Amazon SageMaker Unified Studio (preview) provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. To use Amazon Bedrock FMs, grant access to base models.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. All the code, Talend job, and the BI report are version controlled using Git.
Hence the drive to provide ML as a service to the Data & Tech team’s internal customers. All they would have to do is just build their model and run with it,” he says. That step, primarily undertaken by developers and data architects, established data governance and data integration. The offensive side?
Aligning business goals to data usage is a key foundation. There is no digital transformation without business-aligned data control,” Capgemini Executive Steve Jones adds. “The architectural model of big data is fundamental to this.”. Everything comes down to what organizations do with data.
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation. Business Context. Business Content.
Solution To address the challenge, ATPCO sought inspiration from a modern data mesh architecture. Implementation Now, we’ll walk through how ATPCO implemented their solution to solve the challenges of analysts discovering, getting access to, and using data quickly to help their airline customers. Select Create environment profile.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
At a time when AI is exploding in popularity and finding its way into nearly every facet of business operations, data has arguably never been more valuable. More recently, that value has been made clear by the emergence of AI-powered technologies like generative AI (GenAI) and the use of Large Language Models (LLMs).
With each game release and update, the amount of unstructured data being processed grows exponentially, Konoval says. This volume of data poses serious challenges in terms of storage and efficient processing,” he says. To address this problem RetroStyle Games invested in datalakes. Quality is job one.
Foundation When the teams don’t have a robust enough skillset, it can require more time to model and process data, and cause longer latency and lower dataquality. To address this, the foundation role provides an already processed dataset as a generic datamodel for data commonly use cases used by many consumers.
Over the next decade, the companies that will beat competitors will be “model-driven” businesses. These companies often undertake large data science efforts in order to shift from “data-driven” to “model-driven” operations, and to provide model-underpinned insights to the business. anomaly detection).
In fact, AMA collects a huge amount of structured and unstructured data from bins, collection vehicles, facilities, and user reports, and until now, this data has remained disconnected, managed by disparate systems and interfaces, through Excel spreadsheets.
In addition to the tracking of relationships and quality metrics, DataOps Observability journeys allow users to establish baselines?concrete concrete expectations for run schedules, run durations, dataquality, and upstream and downstream dependencies. And she’ll know when newer data will arrive.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content