This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
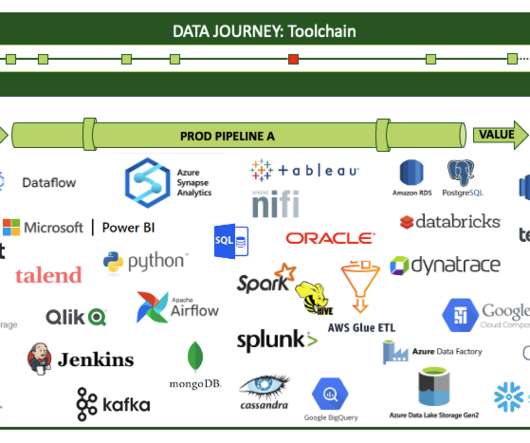
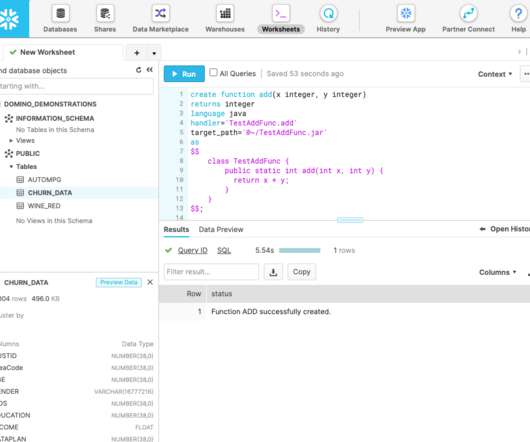
data engineers delivered over 100 lines of code and 1.5 dataquality tests every day to support a cast of analysts and customers. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
In recent years, datalakes have become a mainstream architecture, and dataquality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex dataquality rulesets over a predefined test dataset.
They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. These rules assess the data based on fixed criteria reflecting current business states. We are excited to talk about how to use dynamic rules , a new capability of AWS Glue DataQuality.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
AWS Lake Formation and the AWS Glue Data Catalog form an integral part of a data governance solution for datalakes built on Amazon Simple Storage Service (Amazon S3) with multiple AWS analytics services integrating with them. In 2023, we added support for column-level statistics for tables in the Data Catalog.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Historic Balance – compares current data to previous or expected values.
In addition to the tracking of relationships and quality metrics, DataOps Observability journeys allow users to establish baselines?concrete concrete expectations for run schedules, run durations, dataquality, and upstream and downstream dependencies. And she’ll know when newer data will arrive.
Gartner agrees that synthetic data can help solve the data availability problem for AI products, as well as privacy, compliance, and anonymization challenges. Web scraping activity can be direct, carried out by the same subject who develops the model, or indirect, carried out from third-party datalakes.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
Data observability provides insight into the condition and evolution of the data resources from source through the delivery of the data products. Barr Moses of Monte Carlo presents it as a combination of data flow, dataquality, data governance, and data lineage.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI). This can help identify any discrepancies in data values or data types.
In this way, a data scientist benefits from business knowledge that they might not otherwise have access to. The catalog facilitates the synergy of the domain experts’ subject matter expertise with the data scientists statistical and coding expertise. Modern data catalogs surface a wide range of data asset types.
For any data user in an enterprise today, data profiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
However, often the biggest stumbling block is a human one, getting people to buy in to the idea that the care and attention they pay to data capture will pay dividends later in the process. These and other areas are covered in greater detail in an older article, Using BI to drive improvements in dataquality. million ± £0.5
It’s only when companies take their first stab at manually cataloging and documenting operational systems, processes and the associated data, both at rest and in motion, that they realize how time-consuming the entire data prepping and mapping effort is, and why that work is sure to be compounded by human error and dataquality issues.
Data analysts contribute value to organizations by uncovering trends, patterns, and insights through data gathering, cleaning, and statistical analysis. They identify and interpret trends in complex datasets, optimize statistical results, and maintain databases while devising new data collection processes.
What Are the Top Data Challenges to Analytics? The proliferation of data sources means there is an increase in data volume that must be analyzed. Large volumes of data have led to the development of datalakes , data warehouses, and data management systems. Establishes Trust in Data.
At a certain point, as the demand keeps growing, the data volumes rapidly increase. Data is no longer stored in CSV files, but in a dedicated, purpose built datalake / data warehouse. Existing preprocessing, data ingestion, and dataquality processes can be converted from Java/Spark into Java UDFs.
Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? You cannot get away from a formalized delivery capability focused on regular, scheduled, structured and reasonably governed data. Datalakes don’t offer this nor should they. E.g. DataLakes in Azure – as SaaS.
That was the Science, here comes the Technology… A Brief Hydrology of DataLakes. Even back then, these were used for activities such as Analytics , Dashboards , Statistical Modelling , Data Mining and Advanced Visualisation. This is the essence of Convergent Evolution.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
The new edition also explores artificial intelligence in more detail, covering topics such as DataLakes and Data Sharing practices. 6) Lean Analytics: Use Data to Build a Better Startup Faster, by Alistair Croll and Benjamin Yoskovitz.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content