This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
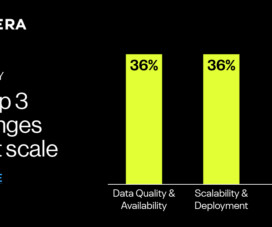
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
This post explores how the shift to a data product mindset is being implemented, the challenges faced, and the early wins that are shaping the future of data management in the Institutional Division. This principle makes sure data accountability remains close to the source, fostering higher dataquality and relevance.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
But because of the infrastructure, employees spent hours on manual data analysis and spreadsheet jockeying. We had plenty of reporting, but very little data insight, and no real semblance of a datastrategy. Second, the manual spreadsheet work resulted in significant manual data entry.
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support. It includes exponential backoff and jitter strategy by adding a random delay of 025% to each retry interval.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
Having a clearly defined digital transformation strategy is an essential best practice for successful digital transformation. But what makes a viable digital transformation strategy? Constructing A Digital Transformation Strategy: Data Enablement. With automation, dataquality is systemically assured.
But, even with the backdrop of an AI-dominated future, many organizations still find themselves struggling with everything from managing data volumes and complexity to security concerns to rapidly proliferating data silos and governance challenges. The benefits are clear, and there’s plenty of potential that comes with AI adoption.
Mark Booth: We have a growth strategy to improve our business, and to support that, we’re driving a transformation in technology and business processes. But the more challenging work is in making our processes as efficient as possible so we capture the right data in our desire to become a more data-driven business.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust datastrategy incorporating a comprehensive data governance approach. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
These formats, exemplified by Apache Iceberg, Apache Hudi, and Delta Lake, addresses persistent challenges in traditional datalake structures by offering an advanced combination of flexibility, performance, and governance capabilities. For more information, refer to What are deletion vectors?
It’s stored in corporate data warehouses, datalakes, and a myriad of other locations – and while some of it is put to good use, it’s estimated that around 73% of this data remains unexplored. Improving dataquality. Unexamined and unused data is often of poor quality. Data augmentation.
When it comes to implementing and managing a successful BI strategy we have always proclaimed: start small, use the right BI tools , and involve your team. You need to determine if you are going with an on-premise or cloud-hosted strategy. You want an organization-wide buy-in of your business intelligence strategy.
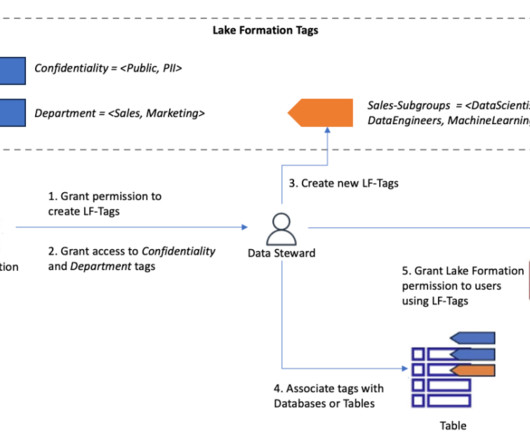
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI). For more details, see Strangler Fig Application.
As they continue to implement their Digital First strategy for speed, scale and the elimination of complexity, they are always seeking ways to innovate, modernize and also streamline data access control in the Cloud. BMO has accumulated sensitive financial data and needed to build an analytic environment that was secure and performant.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
Birgit Fridrich, who joined Allianz as sustainability manager responsible for ESG reporting in late 2022, spends many hours validating data in the company’s Microsoft Sustainability Manager tool. Dataquality is key, but if we’re doing it manually there’s the potential for mistakes.
To companies entrenched in decades-old business and IT processes, data fiefdoms, and legacy systems, the task may seem insurmountable. Develop a strategy to liberate data . Which type(s) of storage consolidation you use depends on the data you generate and collect. . Just starting out with analytics?
Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation. The analysts call this a data mesh or data fabric strategy.
Selling the value of data transformation Iyengar and his team are 18 months into a three- to five-year journey that started by building out the data layer — corralling data sources such as ERP, CRM, and legacy databases into data warehouses for structured data and datalakes for unstructured data.
This allows for transparency, speed to action, and collaboration across the group while enabling the platform team to evangelize the use of data: Altron engaged with AWS to seek advice on their datastrategy and cloud modernization to bring their vision to fruition.
The complexities of compliance In May, the Italian Data Protection Authority highlighted how training models on which gen AI systems are based always require a huge amount of data, often obtained by web scraping, or a massive and indiscriminate collection carried out on the web, it says.
In addition, by properly separating data and processing, it becomes effortless for the teams and organizations to share, manage, and inherit processes that were traditionally confined to individual PCs. Here, the foundation role takes the lead in compiling the knowledge of domain experts and making data suitable for analysis.
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
In Foundry’s 2022 Data & Analytics Study , 88% of IT decision-makers agree that data collection and analysis have the potential to fundamentally change their business models over the next three years. The ability to pivot quickly to address rapidly changing customer or market demands is driving the need for real-time data.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
The application gets prompt templates from an S3 datalake and creates the engineered prompt. The user interaction is stored in a datalake for downstream usage and BI analysis. The application sends the prompt to Amazon Bedrock and retrieves the LLM output.
Managers see data as relevant in the context of digitalization, but often think of data-related problems as minor details that have little strategic importance. Thus, it is taken for granted that companies should have a datastrategy. But what is the scope of an effective strategy and who is affected by it?
Making the most of enterprise data is a top concern for IT leaders today. With organizations seeking to become more data-driven with business decisions, IT leaders must devise datastrategies gear toward creating value from data no matter where — or in what form — it resides. Quality is job one.
For Melanie Kalmar, the answer is data literacy and a strong foundation in tech. How do data and digital technologies impact your business strategy? At the core, digital at Dow is about changing how we work, which includes how we interact with systems, data, and each other to be more productive and to grow.
In fact, AMA collects a huge amount of structured and unstructured data from bins, collection vehicles, facilities, and user reports, and until now, this data has remained disconnected, managed by disparate systems and interfaces, through Excel spreadsheets.
Usually, organizations will combine different domain topologies, depending on the trade-offs, and choose to focus on specific aspects of data mesh. Once accomplished, an effective implementation spurs a mindset in which organizations prioritize and value data for decision-making, formulating strategies, and day-to-day operations.
Every day, organizations of every description are deluged with data from a variety of sources, and attempting to make sense of it all can be overwhelming. So a strong business intelligence (BI) strategy can help organize the flow and ensure business users have access to actionable business insights. “By
Big Data technology in today’s world. Did you know that the big data and business analytics market is valued at $198.08 Or that the US economy loses up to $3 trillion per year due to poor dataquality? quintillion bytes of data which means an average person generates over 1.5 megabytes of data every second?
Previously, there were three types of data structures in telco: . Entity data sets — i.e. marketing datalakes . The result has been an extraordinary volume of data redundancy across the business, leading to disaggregated datastrategy, unknown compliance exposures, and inconsistencies in data-based processes. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content