This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
data engineers delivered over 100 lines of code and 1.5 dataqualitytests every day to support a cast of analysts and customers. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
A DataOps Approach to DataQuality The Growing Complexity of DataQualityDataquality issues are widespread, affecting organizations across industries, from manufacturing to healthcare and financial services. 73% of data practitioners do not trust their data (IDC).
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
In recent years, datalakes have become a mainstream architecture, and dataquality validation is a critical factor to improve the reusability and consistency of the data. In this post, we provide benchmark results of running increasingly complex dataquality rulesets over a predefined test dataset.
Ensuring that data is available, secure, correct, and fit for purpose is neither simple nor cheap. Companies end up paying outside consultants enormous fees while still having to suffer the effects of poor dataquality and lengthy cycle time. . When a job is automated, there is little advantage to outsourcing. .
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
Your Chance: Want to test an agile business intelligence solution? Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. Test BI in a small group and deploy the software internally. Finalize testing. Test throughout the lifecycle.
The core issue plaguing many organizations is the presence of out-of-control databases or datalakes characterized by: Unrestrained Data Changes: Numerous users and tools incessantly alter data, leading to a tumultuous environment. Monitor freshness, schema changes, volume, and column health are standard.
The data engineer then emails the BI Team, who refreshes a Tableau dashboard. Figure 1: Example data pipeline with manual processes. There are no automated tests , so errors frequently pass through the pipeline. Figure 2: Example data pipeline with DataOps automation. Adding Tests to Reduce Stress.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. Manually upgrading, testing, and deploying over 5,000 jobs every few quarters was time consuming, error prone, costly, and not sustainable.
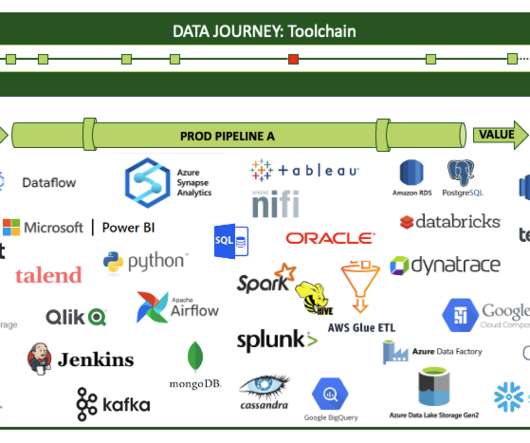
As he thinks through the various journeys that data take in his company, Jason sees that his dashboard idea would require extracting or testing for events along the way. So, the only way for a data journey to truly observe what’s happening is to get his tools and pipelines to auto-report events. Data and tool tests.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI). Additional considerations – Factor in additional tasks beyond schema conversion.
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation. Business Context.
Real-Time Intelligence, on the other hand, takes that further by supporting data in AWS, Google Cloud Platform, Kafka installations, and on-prem installations. “We We introduced the Real-Time Hub,” says Arun Ulagaratchagan, CVP, Azure Data at Microsoft. Morrone notes that in the next race, the company will test Azure Private 5G Core.
It’s common to ingest multiple data sources into Amazon Redshift to perform analytics. Often, each data source will have its own processes of creating and maintaining data, which can lead to dataquality challenges within and across sources. Answering questions as simple as “How many unique customers do we have?”
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
The complexities of compliance In May, the Italian Data Protection Authority highlighted how training models on which gen AI systems are based always require a huge amount of data, often obtained by web scraping, or a massive and indiscriminate collection carried out on the web, it says.
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities.
In Foundry’s 2022 Data & Analytics Study , 88% of IT decision-makers agree that data collection and analysis have the potential to fundamentally change their business models over the next three years. The ability to pivot quickly to address rapidly changing customer or market demands is driving the need for real-time data.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. This separation means changes can be tested thoroughly before being deployed to live operations. It helps HEMA centralize all data assets across disparate data stacks into a single catalog.
Unless, of course, the rest of their data also resides in the Google Cloud. In this post we showcase how we used AWS Glue to move siloed digital analytics data, with inconsistent arrival times, to AWS S3 (our DataLake) and our central data warehouse (DWH), Snowflake. It consists of full-day and intraday tables.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Dataquality using table rollback. Only metadata will be regenerated.
As organizations become data-driven and awash in an overwhelming amount of data from multiple data sources (AI, IOT, ML, etc.), organizations will need to get a better handle on dataquality and focus on data management processes and practices.
Before starting any production workloads after migration, you need to test your new workflows to ensure no disruption to production systems. Migrating workloads to AWS Glue AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources.
Tricentis is the global leader in continuous testing for DevOps, cloud, and enterprise applications. Speed changes everything, and continuous testing across the entire CI/CD lifecycle is the key. Tricentis instills that confidence by providing software tools that enable Agile Continuous Testing (ACT) at scale.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Domain teams should continually monitor for data errors with data validation checks and incorporate data lineage to track usage. Establish and enforce data governance by ensuring all data used is accurate, complete, and compliant with regulations. This calls for additional planning, documentation, and testing.
With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics in 2021, it became more critical to scale and generate near-real-time data. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes.
Some data seems more analytical, while other is operational (external facing). We recommend identifying the data sources and tables that need to be considered to be governed, establishing the governance owner & dataquality details, and saving those details in the catalog. Where do you govern? Here’s an example.
For any data user in an enterprise today, data profiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
Therefore, it’s crucial to keep the schema definition in the Schema Registry and the Data Catalog table in sync. To avoid this, it’s recommended to use a dataquality check mechanism to identify such anomalies and take appropriate action in case of unexpected behavior. test-schema-registry MSKSchemaName Name of the schema.
It’s only when companies take their first stab at manually cataloging and documenting operational systems, processes and the associated data, both at rest and in motion, that they realize how time-consuming the entire data prepping and mapping effort is, and why that work is sure to be compounded by human error and dataquality issues.
As the latest iteration in this pursuit of high-qualitydata sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, dataquality , and ETL/ELT. This produces end-to-end lineage so business and technology users alike can understand the state of a datalake and/or lake house.
Le aziende che sperimentano la GenAI di solito creano account di livello aziendale con servizi basati sul cloud, come ChatGPT di OpenAI o Claude di Anthropic, e i primi test sul campo e i vantaggi in termini di produttività le portano a cercare altre opportunità per implementare la tecnologia. “Le
Storage-centric approach In the storage-centric approach, people try to address data silos by throwing everything in a datalake or a data warehouse. But, although, this helps somewhat in terms of architecture, soon these datalakes become unwieldy.
“La qualità del dato viene ottenuta definendo un processo che coinvolge tutti gli attori aziendali e gli strumenti di misurazione appositi”, evidenzia Francesco Saverio Colasuonno, Data & Analytics Office Manager di INAIL. “Le Ma ci aspettiamo di estenderla ad altri use-case”.
At a certain point, as the demand keeps growing, the data volumes rapidly increase. Data is no longer stored in CSV files, but in a dedicated, purpose built datalake / data warehouse. Existing preprocessing, data ingestion, and dataquality processes can be converted from Java/Spark into Java UDFs.
Amazon Redshift helps you break down the data silos and allows you to run unified, self-service, real-time, and predictive analytics on all data across your operational databases, datalake, data warehouse, and third-party datasets with built-in governance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content