This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of datawarehouses, data marts, and data […]. The post DataWarehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or DataWarehouse- Which is Better? We can use it to represent facts, figures, and other information that we can use to make decisions. appeared first on Analytics Vidhya.
Overview Understand the meaning of datalake and datawarehouse We will see what are the key differences between DataWarehouse and DataLake. The post What are the differences between DataLake and DataWarehouse? appeared first on Analytics Vidhya.
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between datawarehouses and datalakes and share some of Ventana Research’s findings on the subject.
However, they often struggle with increasingly larger data volumes, reverting back to bottlenecking data access to manage large numbers of data engineering requests and rising data warehousing costs. This new open data architecture is built to maximize data access with minimal data movement and no data copies.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. DataWarehouse appeared first on Analytics Vidhya.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
This article was published as a part of the Data Science Blogathon. Introduction We are all pretty much familiar with the common modern cloud datawarehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a datawarehouse compute engine […].
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with datalakes. DataWarehouse.
An organization’s data is copied for many reasons, namely ingesting datasets into datawarehouses, creating performance-optimized copies, and building BI extracts for analysis. Read this whitepaper to learn: Why organizations frequently end up with unnecessary data copies.
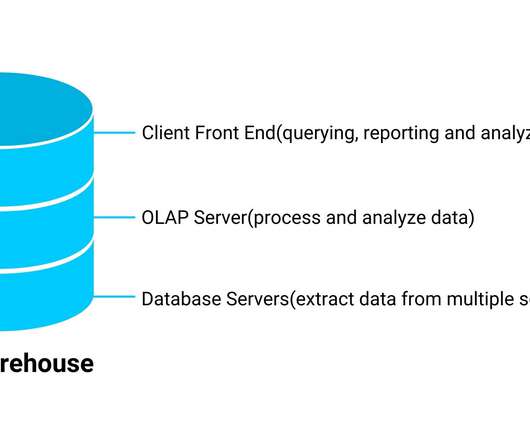
Datalakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and DataLakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
The Right Solution for Your Data: Cloud DataLakes and Data Lakehouses. Datalakes have experienced a fairly robust resurgence over the last few years, specifically cloud datalakes. A Wave of Cloud-Native, Distributed Data Frameworks.
It has a drag and drop visual interface and can connect to databases, enterprise datawarehouses, datalakes, cloud storage, business applications and social media. The platform also supports push-down processing for data prep and ETL inside databases to minimize data movement and optimize performance.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and datawarehouse capabilities are required to leverage this data.
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Business units access clean, standardized data.
Increasingly, enterprises are leveraging cloud datalakes as the platform used to store data for analytics, combined with various compute engines for processing that data. Read this paper to learn about: The value of cloud datalakes as the new system of record.
Another offering that AWS announced to support the integration is the SageMaker Data Lakehouse , aimed at helping enterprises unify data across Amazon S3 datalakes and Amazon Redshift datawarehouses.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. The post Warehouse, Lake or a Lakehouse – What’s Right for you?
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and datawarehouses. Determine your preparedness.
Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform. Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […].
Amazon Redshift has established itself as a highly scalable, fully managed cloud datawarehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. Now, theyre able to build and collaborate with their data and tools available in one experience, dramatically reducing time-to-value.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift datawarehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Uniteds embrace of SageMaker and Bedrock as well as Amazon Q is going to be a game changer for building data products, said Mai-LanTomsenBukovec, AWS vice president of technology, who pointed to United Data Hub as a transformational component in its AI journey at re:Invent.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Solving the small file problem and improving query performance In modern data architectures, stream processing engines such as Amazon EMR are often used to ingest continuous streams of data into datalakes using Apache Iceberg. They decided to focus on four runtime engines. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Talend data integration software offers an open and scalable architecture and can be integrated with multiple datawarehouses, systems and applications to provide a unified view of all data. Its code generation architecture uses a visual interface to create Java or SQL code.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content