This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprisedatawarehouses in the past, so let’s contrast them with datalakes.
Rapidminer is a visual enterprisedata science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Another offering that AWS announced to support the integration is the SageMaker Data Lakehouse , aimed at helping enterprises unify data across Amazon S3 datalakes and Amazon Redshift datawarehouses.
Data fuels the modern enterprise — today more than ever, businesses compete on their ability to turn big data into essential business insights. Increasingly, enterprises are leveraging cloud datalakes as the platform used to store data for analytics, combined with various compute engines for processing that data.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform. Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […].
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift datawarehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
Governance features including fine-grained access control are built into SageMaker Unified Studio using Amazon SageMaker Catalog to help you meet enterprise security requirements across your entire data estate.
Data mesh and DataOps provide the organization, enterprise architecture, and workflow automation that together enable a relatively small data team to address the analytics needs of hundreds of active business users. Figure 1: Data requirements for phases of the drug product lifecycle. The new Recipes run, and BOOM!
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Uniteds embrace of SageMaker and Bedrock as well as Amazon Q is going to be a game changer for building data products, said Mai-LanTomsenBukovec, AWS vice president of technology, who pointed to United Data Hub as a transformational component in its AI journey at re:Invent. That number has increased to 21% in just 18 months.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. DAMA-DMBOK 2.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. For many enterprises and large organizations, it is not feasible to have one processing engine or tool to deal with the various business requirements. This post is co-written with Andries Engelbrecht and Scott Teal from Snowflake.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
The data mesh design pattern breaks giant, monolithic enterprisedata architectures into subsystems or domains, each managed by a dedicated team. But first, let’s define the data mesh design pattern. The past decades of enterprisedata platform architectures can be summarized in 69 words.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It served many enterprise use cases across API feeds, content mastering, and analytics interfaces.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Ostensibly, the new product represents Microsoft’s transition to a newer, more cloud-friendly ERP for midsized enterprises. OLAP reporting has traditionally relied on a datawarehouse. OLAP reporting based on a datawarehouse model is a well-proven solution for companies with robust reporting requirements.
Why should you integrate data governance (DG) and enterprise architecture (EA)? Two of the biggest challenges in creating a successful enterprise architecture initiative are: collecting accurate information on application ecosystems and maintaining the information as application ecosystems change.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. This post is co-written with Amit Gilad, Alex Dickman and Itay Takersman from Cloudinary. They decided to focus on four runtime engines.
Given the diverse data integration needs of customers, AWS offers a robust data integration system through multiple services including Amazon EMR , Amazon Athena , Amazon Managed Workflows for Apache Airflow (Amazon MWAA) , Amazon Managed Streaming for Apache Kafka (MSK) , Amazon Kinesis , and others.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.
For more sophisticated multidimensional reporting functions, however, a more advanced approach to staging data is required. The DataWarehouse Approach. Datawarehouses gained momentum back in the early 1990s as companies dealing with growing volumes of data were seeking ways to make analytics faster and more accessible.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, datawarehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
In this post, Morningstar’s DataLake Team Leads discuss how they utilized tag-based access control in their datalake with AWS Lake Formation and enabled similar controls in Amazon Redshift. We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. This will take a few minutes to run and will establish a query history for the tpcds data. Choose Run all on each notebook tab.
The sheer scale of data being captured by the modern enterprise has necessitated a monumental shift in how that data is stored. What was at first a data stream has morphed into a data river as enterprise businesses are harvesting reams of data from every conceivable input across every conceivable business function.
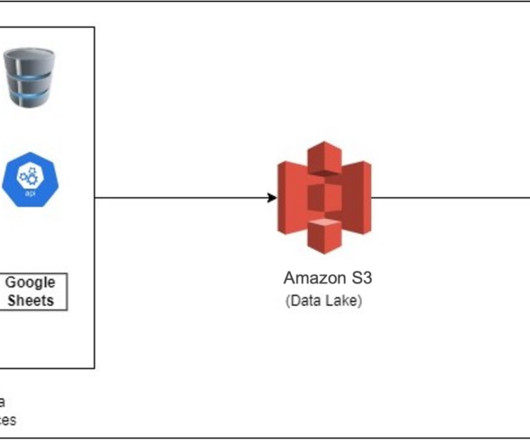
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and datalakes fail when applied at the scale and speed of today’s organizations.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
This leads to having data across many instances of datawarehouses and datalakes using a modern data architecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation.
Enterprisedata is brought into datalakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on.
One-time and complex queries are two common scenarios in enterprisedata analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. Here, data modeling uses dbt on Amazon Redshift.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has worked with building datawarehouses and big data solutions for over 13 years.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content