This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. Data collection is critical for businesses to make informed decisions, understand customers’ […].
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with datalakes. DataWarehouse.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and datawarehouse capabilities are required to leverage this data.
Data architectures to support reporting, business intelligence, and analytics have evolved dramatically over the past 10 years. Download this TDWI Checklist report to understand: How your organization can make this transition to a modernized data architecture.
Some of these are emerging topics and others are developments on existing concepts, but all of them will inform our thinking in the coming year. The Right Solution for Your Data: Cloud DataLakes and Data Lakehouses. A Wave of Cloud-Native, Distributed Data Frameworks.
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Business units access clean, standardized data.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
Chief among these is United ChatGPT for secure employee experimental use and an external-facing LLM that better informs customers about flight delays, known as Every Flight Has a Story, that has already boosted customer satisfaction by 6%, Birnbaum notes. Historically United storytellers had to manually edit templates, which took time.
Amazon Redshift has established itself as a highly scalable, fully managed cloud datawarehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
It’s important to look beyond the surface, however, because there are some critical architectural changes that could dramatically affect how end-users get information out of the system. Let’s start with some background information. The Data Security Problem: How We Got Here. Option 3: Azure DataLakes.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
With the exponential growth of data, companies are handling huge volumes and a wide variety of data including personally identifiable information (PII). PII is a legal term pertaining to information that can identify, contact, or locate a single person. For our solution, we use Amazon Redshift to store the data.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Talend data integration software offers an open and scalable architecture and can be integrated with multiple datawarehouses, systems and applications to provide a unified view of all data. Its code generation architecture uses a visual interface to create Java or SQL code.
Now, instead of making a direct call to the underlying database to retrieve information, a report must query a so-called “data entity” instead. Each data entity provides an abstract representation of business objects within the database, such as, customers, general ledger accounts, or purchase orders. DataLakes.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern data architectures.
AI and ML are the only ways to derive value from massive datalakes, cloud-native datawarehouses, and other huge stores of information. The right data and analytics platform can help you bridge the gap between your current AI and analytics paradigm and where you want your company to be in the future. .
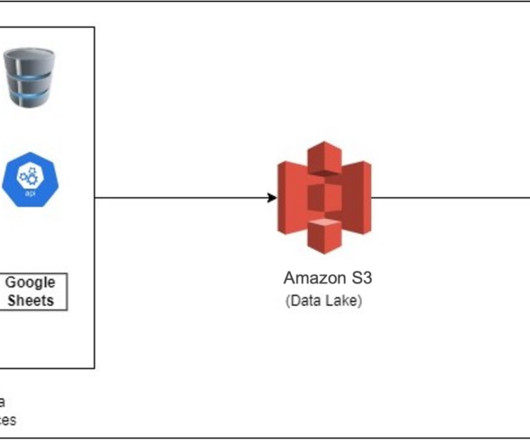
Amazon AppFlow bridges the gap between Google applications and Amazon Redshift, empowering organizations to unlock deeper insights and drive data-informed decisions. In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. This will take a few minutes to run and will establish a query history for the tpcds data. Choose Run all on each notebook tab.
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. Solution overview The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services.
With “Empowering Investor Success” as the core motto, Morningstar aims at providing our investors and advisors with the tools and information they need to make informed investment decisions. We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift.
This leads to having data across many instances of datawarehouses and datalakes using a modern data architecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation.
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. in Delta Lake public document.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications.
Today, more than 90% of its applications run in the cloud, with most of its data is housed and analyzed in a homegrown enterprise datawarehouse. Like many CIOs, Carhartt’s top digital leader is aware that data is the key to making advanced technologies work. Today, we backflush our datalake through our datawarehouse.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
With Amazon Redshift, you can use standard SQL to query data across your datawarehouse, operational data stores, and datalake. Migrating a datawarehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.
Enterprise data is brought into datalakes and datawarehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Can it also help write SQL queries? The answer is yes.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. For more information, refer to Retry Amazon S3 requests with EMRFS. availability.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. Here, data modeling uses dbt on Amazon Redshift.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content