This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or DataWarehouse- Which is Better? appeared first on Analytics Vidhya.
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and datawarehouse capabilities are required to leverage this data.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with datalakes. DataWarehouse.
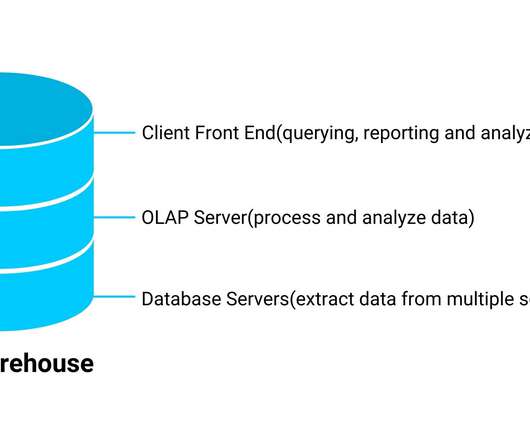
Datalakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and DataLakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
The Right Solution for Your Data: Cloud DataLakes and Data Lakehouses. Datalakes have experienced a fairly robust resurgence over the last few years, specifically cloud datalakes. A Wave of Cloud-Native, Distributed Data Frameworks. Both are seeing strong growth.
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
United claims to be among the earliest users of the Amazon SageMaker ML platform, and it has leveraged its own United Data Hub and AWS Bedrock-based Mars ML platform to create this first batch of production gen AI LLMs. People hear the specifics, and they understand it and their blood pressure goes down.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis.
It combines SQL analytics, data processing, AI development, data streaming, business intelligence, and search analytics. Another offering that AWS announced to support the integration is the SageMaker Data Lakehouse , aimed at helping enterprises unify data across Amazon S3 datalakes and Amazon Redshift datawarehouses.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Why: Data Makes It Different. In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices?
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Amazon SageMaker brings together widely adopted AWS machine learning (ML) and analytics capabilities and addresses the challenges of harnessing organizational data for analytics and AI through unified access to tools and data with governance built in. The data analyst then discovers it and creates a comprehensive view of their market.
Datalake is a newer IT term created for a new category of data store. But just what is a datalake? According to IBM, “a datalake is a storage repository that holds an enormous amount of raw or refined data in native format until it is accessed.” That makes sense. I think the […].
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and datawarehouses. Determine your preparedness. Conclusion.
We’ve covered the basic ideas behind data mesh and some of the difficulties that must be managed. Below is a discussion of a data mesh implementation in the pharmaceutical space. DataKitchen has extensive experience using the data mesh design pattern with pharmaceutical company data. . The new Recipes run, and BOOM!
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. This innovation drives an important change: you’ll no longer have to copy or move data between datalake and datawarehouses.
Amazon Redshift is a fast, fully managed petabyte-scale cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. If these concerns were not addressed, the customer would be prevented from growing their user base.
Talend data integration software offers an open and scalable architecture and can be integrated with multiple datawarehouses, systems and applications to provide a unified view of all data. Its code generation architecture uses a visual interface to create Java or SQL code.
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. Why Cloudinary chose Apache Iceberg Apache Iceberg is a high-performance table format for huge analytic workloads.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
This approach comes with a heavy computational cost in terms of processing and distributing the data across multiple tables while ensuring the system is ACID-compliant at all times, which can negatively impact performance and scalability. These types of queries are suited for a datawarehouse. This is called index overloading.
Given the importance of data in the world today, organizations face the dual challenges of managing large-scale, continuously incoming data while vetting its quality and reliability. One of its key features is the ability to manage data using branches. One of its key features is the ability to manage data using branches.
First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. See the pattern? The problem is not “you.”
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. This post is co-written with Andries Engelbrecht and Scott Teal from Snowflake.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and data architecture and views the data organization from the perspective of its processes and workflows.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content