This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Today we are pleased to announce a new class of Amazon CloudWatch metrics reported with your pipelines built on top of AWS Glue for Apache Spark jobs. The new metrics provide aggregate and fine-grained insights into the health and operations of your job runs and the data being processed. workerUtilization showed 1.0
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. For example, for certain queries, Athena runtime was 2x–4x faster than Snowflake.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. Refer to API Dimensions & Metrics for details. Outside of work, he enjoys traveling and cooking.
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your data integration pipelines built on AWS Glue. This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana. Choose Administration.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, datawarehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
AI and ML are the only ways to derive value from massive datalakes, cloud-native datawarehouses, and other huge stores of information. There just aren’t enough AI and data science practitioners to go around to tackle this lofty goal. Apply that metric to any other business-critical function.
The sheer scale of data being captured by the modern enterprise has necessitated a monumental shift in how that data is stored. From the humble database through to datawarehouses , data stores have grown both in scale and complexity to keep pace with the businesses they serve, and the data analysis now required to remain competitive.
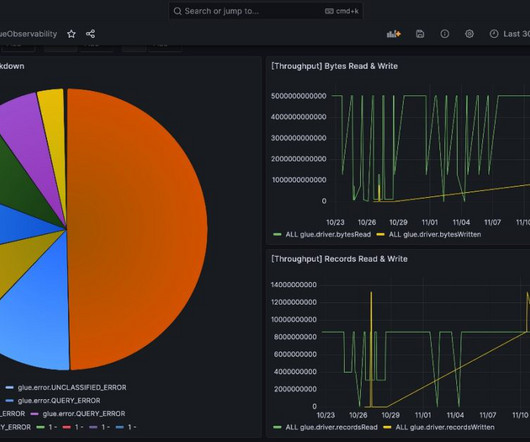
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
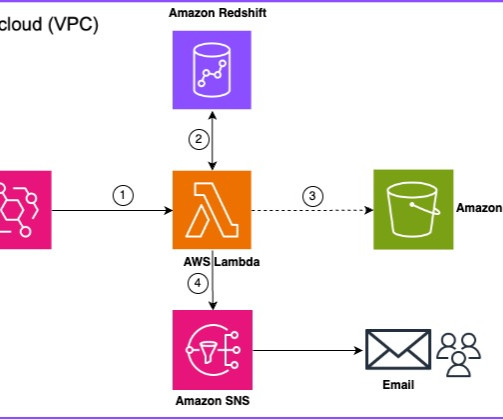
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. The following diagram illustrates this use case’s historical data migration architecture.
AWS Glue Data Quality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug data quality issues. An AWS Glue crawler crawls the results.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we look at three key challenges that customers face with growing data and how a modern datawarehouse and analytics system like Amazon Redshift can meet these challenges across industries and segments. This performance innovation allows Nasdaq to have a multi-use datalake between teams.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and datalakes can become equally challenging.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. This post also includes example SQLs, which you can run on your own Redshift Serverless datawarehouse to experience the benefits of this feature.
These processes retrieve data from around 90 different data sources, resulting in updating roughly 2,000 tables in the datawarehouse and 3,000 external tables in Parquet format, accessed through Amazon Redshift Spectrum and a datalake on Amazon Simple Storage Service (Amazon S3). We started with 115 dc2.large
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Dealing with Data is your window into the ways Data Teams are tackling the challenges of this new world to help their companies and their customers thrive. In recent years we’ve seen data become vastly more available to businesses. This has allowed companies to become more and more data driven in all areas of their business.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
There’s a recent trend toward people creating datalake or datawarehouse patterns and calling it data enablement or a data hub. DataOps expands upon this approach by focusing on the processes and workflows that create data enablement and business analytics. DataOps Process Hub.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from datawarehouses. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
It automatically provisions and intelligently scales datawarehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool. Open the workgroup you want to monitor.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
Current economic conditions call for greater visibility to inventory and the supply chain and closer attention to key financial metrics. Many AX customers have invested heavily in datawarehouse solutions or in robust Power BI implementations that produce considerably more powerful reports and dashboards.
To run analytics on your operational data, you might build a solution that is a combination of a database, a datawarehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. What is a dimensional data model? What is a dimensional data model? What is a data vault?
Most current data architectures were designed for batch processing with analytics and machine learning models running on datawarehouses and datalakes. What metrics are used to understand the business impact of real-time AI? It isn’t easy.
Stream processing, however, can enable the chatbot to access real-time data and adapt to changes in availability and price, providing the best guidance to the customer and enhancing the customer experience. When the model finds an anomaly or abnormal metric value, it should immediately produce an alert and notify the operator.
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant datalake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
Stout, for instance, explains how Schellman addresses integrating its customer relationship management (CRM) and financial data. “A A lot of business intelligence software pulls from a datawarehouse where you load all the data tables that are the back end of the different software,” she says. “Or
These nodes can implement analytical platforms like datalake houses, datawarehouses, or data marts, all united by producing data products. For instance, one enhancement involves integrating cross-functional squads to support data literacy.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that enables you to analyze your data at scale. She has been building datawarehouse solutions for over 20 years and specializes in Amazon Redshift. Vamsi Bhadriraju is a Data Architect at AWS.
You can then run enhanced analysis on this DynamoDB data with the rich capabilities of Amazon Redshift, such as high-performance SQL, built-in machine learning (ML) and Spark integrations, materialized views (MV) with automatic and incremental refresh, data sharing, and the ability to join data across multiple data stores and datalakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content