This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud datawarehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
Datalakes and datawarehouses are probably the two most widely used structures for storing data. DataWarehouses and DataLakes in a Nutshell. A datawarehouse is used as a central storage space for large amounts of structured data coming from various sources.
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
The adoption of cloud environments for analytic workloads has been a key feature of the data platforms sector in recent years. For two-thirds (66%) of participants in ISG’s DataLake Dynamic Insights Research, the primary data platform used for analytics is cloud based.
Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Initially, datawarehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. Now, theyre able to build and collaborate with their data and tools available in one experience, dramatically reducing time-to-value.
Talend is a data integration and management software company that offers applications for cloud computing, big data integration, application integration, data quality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. The tools to transform your business are here.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift datawarehouse. times better price performance than other cloud datawarehouses.
Given the diverse data integration needs of customers, AWS offers a robust data integration system through multiple services including Amazon EMR , Amazon Athena , Amazon Managed Workflows for Apache Airflow (Amazon MWAA) , Amazon Managed Streaming for Apache Kafka (MSK) , Amazon Kinesis , and others.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. All ML projects are software projects.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
But what are the right measures to make the datawarehouse and BI fit for the future? Can the basic nature of the data be proactively improved? The following insights came from a global BARC survey into the current status of datawarehouse modernization. What role do technology and IT infrastructure play?
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
It sells a myriad of different software products, including a growing portfolio of software-as-a-service (SaaS) offerings. OLAP reporting has traditionally relied on a datawarehouse. OLAP reporting based on a datawarehouse model is a well-proven solution for companies with robust reporting requirements.
Today, many customers build data quality validation pipelines using its Data Quality Definition Language (DQDL) because with static rules, dynamic rules , and anomaly detection capability , its fairly straightforward. One of its key features is the ability to manage data using branches. Sotaro Hikita is a Solutions Architect.
Solving the small file problem and improving query performance In modern data architectures, stream processing engines such as Amazon EMR are often used to ingest continuous streams of data into datalakes using Apache Iceberg. They decided to focus on four runtime engines. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from datawarehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Until then though, they don’t necessarily want to spend the time and resources necessary to create a schema to house this data in a traditional datawarehouse. Instead, businesses are increasingly turning to datalakes to store massive amounts of unstructured data. The rise of datawarehouses and datalakes.
In this post, Morningstar’s DataLake Team Leads discuss how they utilized tag-based access control in their datalake with AWS Lake Formation and enabled similar controls in Amazon Redshift. We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift.
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
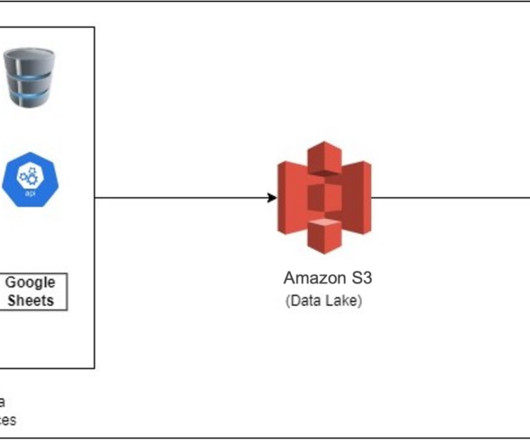
There are various types of pipelines that need to be migrated from the existing integration platform to the AWS Cloud, and the pipelines have different types of sources like Oracle, Microsoft SQL Server, MongoDB, Amazon DocumentDB (with MongoDB compatibility) , APIs, software as a service (SaaS) applications, and Google Sheets.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) datalakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
The sheer scale of data being captured by the modern enterprise has necessitated a monumental shift in how that data is stored. From the humble database through to datawarehouses , data stores have grown both in scale and complexity to keep pace with the businesses they serve, and the data analysis now required to remain competitive.
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. This will take a few minutes to run and will establish a query history for the tpcds data. Choose Run all on each notebook tab.
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. He works based in Tokyo, Japan.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. Here, data modeling uses dbt on Amazon Redshift.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. This is useful for multi-Region access, cross-Region access, disaster recovery, and more.
TIBCO is a large, independent cloud-computing and data analytics software company that offers integration, analytics, business intelligence and events processing software. It enables organizations to analyze streaming data in real time and provides the capability to automate analytics processes.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Traditional datawarehouses, for example, support datasets from multiple sources but require a consistent data structure. Meet the data lakehouse.
In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and datalakes fail when applied at the scale and speed of today’s organizations.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
About the Authors Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. Pradeep Patel is a Software Development Manager on the AWS Glue team. Chuhan Liu is a Software Engineer at AWS Glue.
Datawarehouse vs. databases Traditional vs. Cloud Explained Cloud datawarehouses in your data stack A data-driven future powered by the cloud. We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Datawarehouse vs. databases.
You can create jobs that extract, transform, and load data that is stored in Amazon Simple Storage Service (Amazon S3), Amazon Redshift , and Amazon DynamoDB. Amazon Q Developer can also help you connect to third-party, software as a service (SaaS), and custom sources. XiaoRun Yu is a Software Development Engineer on the AWS Glue team.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, datawarehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content