

Recap of Amazon Redshift key product announcements in 2024
AWS Big Data
DECEMBER 17, 2024
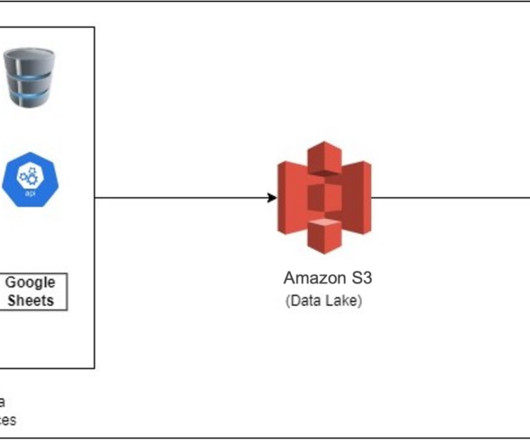
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.


















































Let's personalize your content