This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Datalakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a business intelligence dashboard and take action on immediately.
Talend data integration software offers an open and scalable architecture and can be integrated with multiple datawarehouses, systems and applications to provide a unified view of all data. Its code generation architecture uses a visual interface to create Java or SQL code.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. And move with confidence and trust with built-in governance to address enterprise security needs.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
These improvements are available through the Amazon Q chat experience on the AWS Management Console , and the Amazon SageMaker Unified Studio (preview) visual ETL and notebook interfaces. The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Data analytics and visualization help with many such use cases. It is the time of big data. Understand Your Audience.
These types of queries are suited for a datawarehouse. The goal of a datawarehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud datawarehouse.
For more sophisticated multidimensional reporting functions, however, a more advanced approach to staging data is required. The DataWarehouse Approach. Datawarehouses gained momentum back in the early 1990s as companies dealing with growing volumes of data were seeking ways to make analytics faster and more accessible.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. datazone_env_twinsimsilverdata"."cycle_end";')
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
In this post, Morningstar’s DataLake Team Leads discuss how they utilized tag-based access control in their datalake with AWS Lake Formation and enabled similar controls in Amazon Redshift. We realized we needed a datawarehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your datawarehouse infrastructure. In Cost Explorer, you can visualize daily, monthly, and forecasted spend by combining an array of available filters. Michael Yitayew is a Product Manager for Amazon Redshift based out of New York.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level datawarehouses in massive data scenarios. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. Here, data modeling uses dbt on Amazon Redshift.
Inability to get player level data from the operators. It does not make sense for most casino suppliers to opt for integrated data solutions like datawarehouses or datalakes which are expensive to build and maintain. Evolution from MS Excel to Visual Reporting. Modern Visual Analytics Tools.
In a world increasingly dominated by data, users of all kinds are gathering, managing, visualizing, and analyzing data in a wide variety of ways. One of the downsides of the role that data now plays in the modern business world is that users can be overloaded with jargon and tech-speak, which can be overwhelming.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. Go to the AWS Glue console.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
Azure Data Factory. Azure Data Explorer is used to store and query data in services such as Microsoft Purview, Microsoft Defender for Endpoint, Microsoft Sentinel, and Log Analytics in Azure Monitor. Azure DataLake Analytics.
QuickSight makes it straightforward for business users to visualizedata in interactive dashboards and reports. QuickSight periodically runs Amazon Athena queries to load query results to SPICE and then visualize the latest metric data. The filtered Worker Utilization per Job visualization shows 0.5,
Today, customers are embarking on data modernization programs by migrating on-premises datawarehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. The following diagram illustrates this use case’s historical data migration architecture.
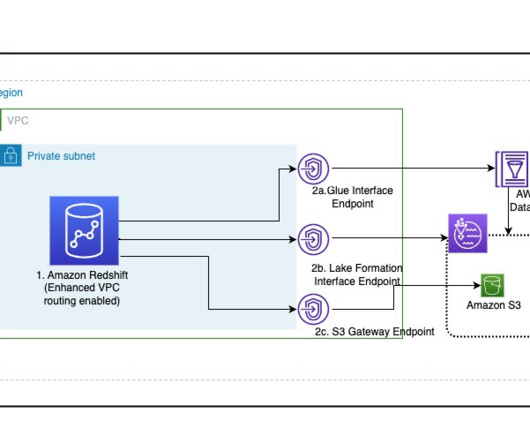
Many customers are extending their datawarehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3).
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a datalake or a datawarehouse. Select the Visual with a blank canvas , because we’re authoring a job from scratch, then choose Create.
It provides insights and metrics related to the performance and effectiveness of data quality processes. In this post, we highlight the seamless integration of Amazon Athena and Amazon QuickSight , which enables the visualization of operational metrics for AWS Glue Data Quality rule evaluation in an efficient and effective manner.
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. In some ways, the data architect is an advanced data engineer.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualizedata and create reports and dashboards from data supplied by other groups.
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. This post also includes example SQLs, which you can run on your own Redshift Serverless datawarehouse to experience the benefits of this feature.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Visual Studio Online. Here they are in my order of importance (based upon my opinion).
These processes retrieve data from around 90 different data sources, resulting in updating roughly 2,000 tables in the datawarehouse and 3,000 external tables in Parquet format, accessed through Amazon Redshift Spectrum and a datalake on Amazon Simple Storage Service (Amazon S3). We started with 115 dc2.large
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and datalakes can become equally challenging.
Use case A typical workload for AWS Glue for Apache Spark jobs is to load data from a relational database to a datalake with SQL-based transformations. The following is a visual representation of an example job where the number of workers is 10. workerUtilization showed 1.0 100%) based on the workload requirements.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP DataWarehouse: a kubernetes-based service that allows business analysts to deploy datawarehouses with secure, self-service access to enterprise data. That Was Then. This is Now.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content