This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deeplearning, artificial intelligence and machine learning (AI/ML) and predictive analytics. Rapidminer Studio is its visual workflow designer for the creation of predictive models.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
Perhaps one of the biggest perks is scalability, which simply means that with good datalake ingestion a small business can begin to handle bigger data numbers. The reality is businesses that are collecting data will likely be doing so on several levels. Proper Scalability.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. Newer methods can work with large amounts of data and are able to unearth latent interactions.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
This introduces further requirements: The scale of operations is often two orders of magnitude larger than in the earlier data-centric environments. Not only is data larger, but models—deeplearning models in particular—are much larger than before. Compute.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. In this example, we searched for columns in our datalake that have similar Column Names ( payload type ) to district ( payload ).
At the lowest layer is the infrastructure, made up of databases and datalakes. We’ve been working on this for over a decade, including transformer-based deeplearning,” says Shivananda. PayPal’s deeplearning models can be trained and put into production in two weeks, and even quicker for simpler algorithms.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. AWS also offers developers the technology to develop smart apps using machine learning and complex algorithms.
The traditional approach for artificial intelligence (AI) and deeplearning projects has been to deploy them in the cloud. Different companies approach this from different angles, and some will naturally gravitate to cloud, based on where their data sets are created and live,” he says.
In the previous blog post in this series, we walked through the steps for leveraging DeepLearning in your Cloudera Machine Learning (CML) projects. Data Ingestion. The raw data is in a series of CSV files. Introduction. For AWS this means at least P3 instances. P2 GPU instances are not supported.
Azure allows you to protect your enterprise data assets, using Azure Active Directory and setting up your virtual network. Other technologies, such as Azure Data Factory, can help process large amounts of data around in the cloud. So, Azure Databricks connects to many different data sources. Azure DataLake Store.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Just starting out with analytics?
Over the past decade, deeplearning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. models are trained on IBM’s curated, enterprise-focused datalake, on our custom-designed cloud-native AI supercomputer, Vela. All watsonx.ai
Utilizamos Azure Data Factory para el proceso de extracción y ETL, el cual genera un datalake con toda la información consolidada almacenándose en un data warehouse basado en tecnología SQL. Epsilon) y datos en Excel alojados en Sharepoint.
L’analisi dei dati attraverso l’apprendimento automatico (machine learning, deeplearning, reti neurali) è la tecnologia maggiormente utilizzata dalle grandi imprese che utilizzano l’IA (51,9%). Le reti neurali sono il modello di machine learning più utilizzato oggi.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments.
Stream Processing – Manage and process multiple streams of real-time data using the most advanced distributed stream processing system – Apache Kafka. Process millions of real-time messages per second to feed into your datalake or for immediate streaming analytics.
Traditional AI tools, especially deeplearning-based ones, require huge amounts of effort to use. You need to collect, curate, and annotate data for any specific task you want to perform. Sometimes the problem with artificial intelligence (AI) and automation is that they are too labor intensive.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. models are trained on IBM’s curated, enterprise-focused datalake. That’s where the foundation model enters the picture. All watsonx.ai
In the case of CDP Public Cloud, this includes virtual networking constructs and the datalake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the data science workflow.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. The capability to rapidly build an AI-powered organization with industry-specific solutions and expertise.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, Machine Learning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Data coming from machines tends to land (aka, data at rest ) in durable stores such as Amazon S3, then gets consumed by Hadoop, Spark, etc. Somehow, the gravity of the data has a geological effect that forms datalakes. DG emerges for the big data side of the world, e.g., the Alation launch in 2012.
Pushing data to a datalake and assuming it is ready for use is shortsighted. Organizations launched initiatives to be “ data-driven ” (though we at Hired Brains Research prefer the term “data-aware”).
Reinforcement learning uses ML to train models to identify and respond to cyberattacks and detect intrusions. Machine learning in financial transactions ML and deeplearning are widely used in banking, for example, in fraud detection. The platform has three powerful components: the watsonx.ai
About Amazon Redshift Thousands of customers rely on Amazon Redshift to analyze data from terabytes to petabytes and run complex analytical queries. With Amazon Redshift, you can get real-time insights and predictive analytics on all of your data across your operational databases, datalake, data warehouse, and third-party datasets.
With new capabilities for self-service and straightforward builder experiences, you can democratize data access for line of business users, analysts, scientists, and engineers. Hear also from Adidas, GlobalFoundries, and University of California, Irvine.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























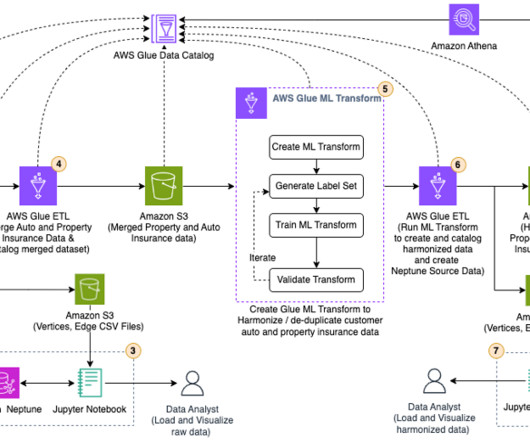













Let's personalize your content