This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deeplearning, artificial intelligence and machinelearning (AI/ML) and predictive analytics. Rapidminer Studio is its visual workflow designer for the creation of predictive models.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
In the previous blog post in this series, we walked through the steps for leveraging DeepLearning in your Cloudera MachineLearning (CML) projects. As a machinelearning problem, it is a classification task with tabular data, a perfect fit for RAPIDS. Data Ingestion. Introduction.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. Newer methods can work with large amounts of data and are able to unearth latent interactions.
Azure allows you to protect your enterprise data assets, using Azure Active Directory and setting up your virtual network. Other technologies, such as Azure Data Factory, can help process large amounts of data around in the cloud. That includes very hot data sources such a real-time processing. Azure DataLake Store.
Much has been written about struggles of deploying machinelearning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. However, the concept is quite abstract. Compute.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. In this example, we searched for columns in our datalake that have similar Column Names ( payload type ) to district ( payload ).
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. AWS also offers developers the technology to develop smart apps using machinelearning and complex algorithms.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, MachineLearning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Machinelearning (ML)—the artificial intelligence (AI) subfield in which machineslearn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Start small with AI. Just starting out with analytics?
L’analisi dei dati attraverso l’apprendimento automatico (machinelearning, deeplearning, reti neurali) è la tecnologia maggiormente utilizzata dalle grandi imprese che utilizzano l’IA (51,9%). Le reti neurali sono il modello di machinelearning più utilizzato oggi.
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments. Watsonx.ai
Utilizamos Azure Data Factory para el proceso de extracción y ETL, el cual genera un datalake con toda la información consolidada almacenándose en un data warehouse basado en tecnología SQL. Epsilon) y datos en Excel alojados en Sharepoint.
Organizations that want to prove the value of AI by developing, deploying, and managing machinelearning models at scale can now do so quickly using the DataRobot AI Platform on Microsoft Azure. AI Platform Single-Tenant SaaS are fully managed by DataRobot and replace disparate machinelearning tools, simplifying management.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machinelearning models lack. models are trained on IBM’s curated, enterprise-focused datalake. That’s where the foundation model enters the picture. All watsonx.ai
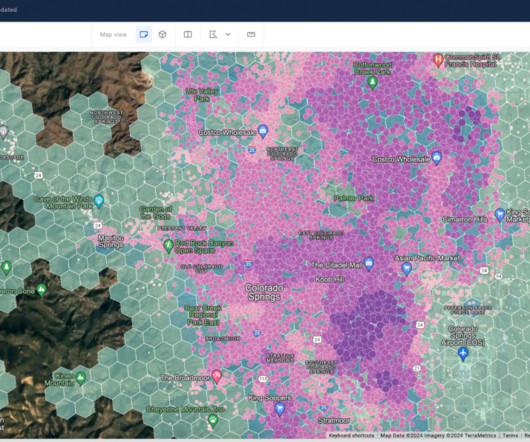
H3-based analytics empower the processing and understanding of delivery data patterns, such as peak times, popular destinations, and high-demand areas. H3 can also help create location-based profiling features for predictive machinelearning (ML) models such as risk-mitigation models.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Plus, the more mature machinelearning (ML) practices place greater emphasis on these kinds of solutions than the less experienced organizations. We keep feeding the monster data.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data.
Pushing data to a datalake and assuming it is ready for use is shortsighted. Organizations launched initiatives to be “ data-driven ” (though we at Hired Brains Research prefer the term “data-aware”).
Predictive analytics: Turning insight into foresight Predictive analytics uses historical data and statistical models or machinelearning algorithms to answer the question, What is likely to happen? Predictive analytics: Seeing whats next Predictive analytics uses patterns in historical data to forecast future outcomes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content