This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deeplearning, artificial intelligence and machine learning (AI/ML) and predictive analytics. Rapidminer Studio is its visual workflow designer for the creation of predictive models.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
Perhaps one of the biggest perks is scalability, which simply means that with good datalake ingestion a small business can begin to handle bigger data numbers. The reality is businesses that are collecting data will likely be doing so on several levels. Proper Scalability. Stores in Raw Format. Uses Powerful Algorithms.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deeplearningmodels in particular—are much larger than before.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. It is also important to have a strong test and learn culture to encourage rapid experimentation.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
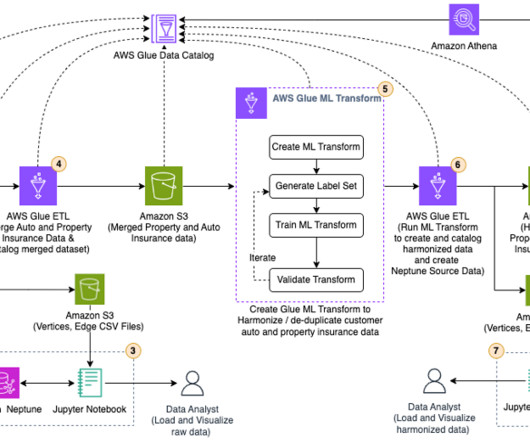
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The workflow begins with an AWS Glue job that converts the CSV files into Apache Parquet data format.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
In the previous blog post in this series, we walked through the steps for leveraging DeepLearning in your Cloudera Machine Learning (CML) projects. RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects. Data Ingestion.
Over the past decade, deeplearning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. Data must be laboriously collected, curated, and labeled with task-specific annotations to train AI models. We stand on the frontier of an AI revolution.
At the lowest layer is the infrastructure, made up of databases and datalakes. We’ve been working on this for over a decade, including transformer-based deeplearning,” says Shivananda. PayPal’s deeplearningmodels can be trained and put into production in two weeks, and even quicker for simpler algorithms.
Traditional AI tools, especially deeplearning-based ones, require huge amounts of effort to use. You need to collect, curate, and annotate data for any specific task you want to perform. And then you need highly specialized, expensive and difficult to find skills to work the magic of training an AI model.
The traditional approach for artificial intelligence (AI) and deeplearning projects has been to deploy them in the cloud. Because it’s common for enterprise software development to leverage cloud environments, many IT groups assume that this infrastructure approach will succeed as well for AI model training.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. AWS also offers a variety of AI model development and delivery platforms , as well as packaged AI-based applications.
Azure allows you to protect your enterprise data assets, using Azure Active Directory and setting up your virtual network. Other technologies, such as Azure Data Factory, can help process large amounts of data around in the cloud. The data is also distributed. So, Azure Databricks connects to many different data sources.
True to their name, generative AI models generate text, images, code , or other responses based on a user’s prompt. But what makes the generative functionality of these models—and, ultimately, their benefits to the organization—possible? That’s where the foundation model enters the picture.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Consider deploying analytics-as-a-service .
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. The answer is that generative AI leverages recent advances in foundation models. Watsonx.ai
H3 can also help create location-based profiling features for predictive machine learning (ML) models such as risk-mitigation models. About Amazon Redshift Thousands of customers rely on Amazon Redshift to analyze data from terabytes to petabytes and run complex analytical queries.
L’analisi dei dati attraverso l’apprendimento automatico (machine learning, deeplearning, reti neurali) è la tecnologia maggiormente utilizzata dalle grandi imprese che utilizzano l’IA (51,9%). Le reti neurali sono il modello di machine learning più utilizzato oggi.
Organizations that want to prove the value of AI by developing, deploying, and managing machine learningmodels at scale can now do so quickly using the DataRobot AI Platform on Microsoft Azure. Models trained in DataRobot can also be easily deployed to Azure Machine Learning, allowing users to host models easier in a secure way.
Instead, we must build robust ML models which take into account inherent limitations in our data and embrace the responsibility for the outcomes. How did the challenges and opportunities related to security, data management, and system architecture get braided together throughout the past ~6 decades of IT?
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Two labeled files have been created for this example.
Data discovery is also critical for data governance , which, when ineffective, can actually hinder organizational growth. And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. Pushing data to a datalake and assuming it is ready for use is shortsighted.
Reinforcement learning uses ML to train models to identify and respond to cyberattacks and detect intrusions. Machine learning in financial transactions ML and deeplearning are widely used in banking, for example, in fraud detection. Spotify uses ML models to generate its song recommendations.
Predictive analytics: Turning insight into foresight Predictive analytics uses historical data and statistical models or machine learning algorithms to answer the question, What is likely to happen? It also makes model training more difficult and production deployment more complex. What will happen? What should we do?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content