This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
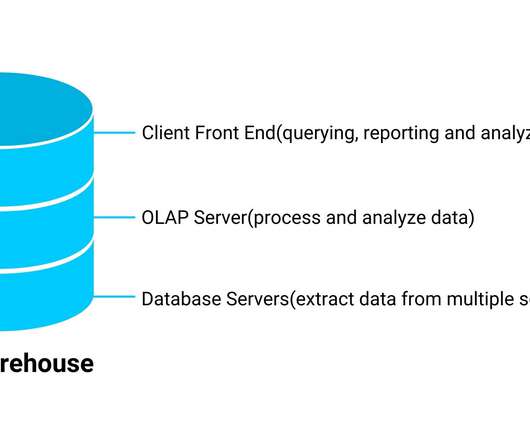
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Image Source: GitHub Table of Contents What is Data Engineering? Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering? appeared first on Analytics Vidhya.
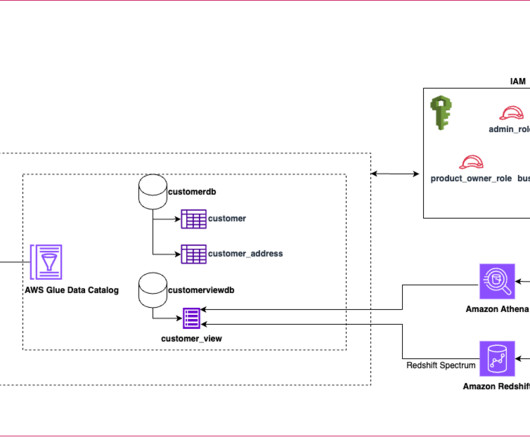
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Data architecture definitionData architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). Curate the data. Ensure security and access controls. Establish a common vocabulary.
When evolving such a partition definition, the data in the table prior to the change is unaffected, as is its metadata. Only data that is written to the table after the evolution is partitioned with the new definition, and the metadata for this new set of data is kept separately. 5 seconds $0.08 8 seconds $0.07
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Whereas a data warehouse will need rigid data modeling and definitions, a datalake can store different types and shapes of data. In a datalake, the schema of the data can be inferred when it’s read, providing the aforementioned flexibility.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Even for the same prompt definition, the model provided a varying list of attributes.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. Refer to the detailed blog post on how you can use this to connect through various other tools.
We pulled these people together, and defined use cases we could all agree were the best to demonstrate our new data capability. Once they were identified, we had to determine we had the right data. Then we migrated the data to our new datalake, and stood up the new platform.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. availability. impl":"org.apache.iceberg.aws.s3.S3FileIO", parquet") df.sortWithinPartitions("review_date").writeTo("dev.db.amazon_reviews_iceberg").append()
Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor data quality. Fragmented systems, inconsistent definitions, legacy infrastructure and manual workarounds introduce critical risks.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Generative SQL uses query history for better accuracy, and you can further improve accuracy through custom context, such as table descriptions, column descriptions, foreign key and primary key definitions, and sample queries. Let’s ask Amazon Q to “Show me the unconverted mana cost and name for all the cards created by Rob Alexander.”
For example, DataOps can be used to automate data integration. Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a datalake. It definitely means redeploying internal and outsourcing budgets to higher value-add activities.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) datalakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems.
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
Apache Hudi is an open table format that brings database and data warehouse capabilities to datalakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance. Under Administration , choose Data catalog settings.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
It enables data engineers, data scientists, and analytics engineers to define the business logic with SQL select statements and eliminates the need to write boilerplate data manipulation language (DML) and datadefinition language (DDL) expressions.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
To achieve this, SAP must continuously harmonize its product landscape and consistently implement uniform standards, for example, in data models and identity and security services, said DSAG CTO Sebastian Westphal. After all, many SAP users have already implemented modern datalake and data lakehouse architectures.
For NoSQL, datalakes, and datalake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. Data Modeling.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
The variables seem endless: data— security , science , storage , mining , management , definition , deletion , integration , accessibility , architecture , collection , governance , and the ever-elusive, data culture. So, they built a data-lake. The datalake, too, took on new purpose.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
First, you must understand the existing challenges of the data team, including the data architecture and end-to-end toolchain. Second, you must establish a definition of “done.” In DataOps, the definition of done includes more than just some working code. Definition of Done. When can you declare it done?
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. Amazon Redshift is built for scale and delivers up to 7.9
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed datalakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. Data Preparation (Apache Spark and Apache Hive) .
In the first post of this series , we described how AWS Glue for Apache Spark works with Apache Hudi, Linux Foundation Delta Lake, and Apache Iceberg datasets tables using the native support of those datalake formats. Even without prior experience using Hudi, Delta Lake or Iceberg, you can easily achieve typical use cases.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. If this is the first time accessing the Lake Formation console, add yourself as the datalake administrator. Now you can set up Lake Formation permissions.
I was at the Gartner Data & Analytics conference in London a couple of weeks ago and I’d like to share some thoughts on what I think was interesting, and what I think I learned…. First, data is by default, and by definition, a liability , because it costs money and has risks associated with it.
Use case A typical workload for AWS Glue for Apache Spark jobs is to load data from a relational database to a datalake with SQL-based transformations. The following is a visual representation of an example job where the number of workers is 10. On the Graphed metrics tab, configure your preferred statistic, period, and so on.
When you register an Environment in CDP, a DataLake is automatically deployed for that environment. DataLake security and governance is managed by a shared set of services running within a DataLake cluster. These are the shared security services encompassed within SDX. .
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. About the authors Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services. Shovan works with customers to design data and machine learning solutions on AWS.
When setting out to build a data warehouse, it’s a common pattern to have a datalake as the source of the data warehouse. The datalake in this context serves a number of important functions: It acts as a central source for multiple applications, not just exclusively for data warehousing purposes.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
By having a single definition of something, complex ETL doesn’t have to be performed repeatedly. Once something is defined, then then everyone can map to the standard definition of what the data means. Compliance: It improves data governance to comply with such regulations as the General Data Protection Regulation (GDPR).
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant datalake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content