This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. You are given the following Instructions for building the Amazon Athena query.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Generative SQL uses query history for better accuracy, and you can further improve accuracy through custom context, such as table descriptions, column descriptions, foreign key and primary key definitions, and sample queries. Let’s try logging in with a different user and see how Amazon Q generative SQL interacts with that user.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
It enables data engineers, data scientists, and analytics engineers to define the business logic with SQL select statements and eliminates the need to write boilerplate data manipulation language (DML) and datadefinition language (DDL) expressions.
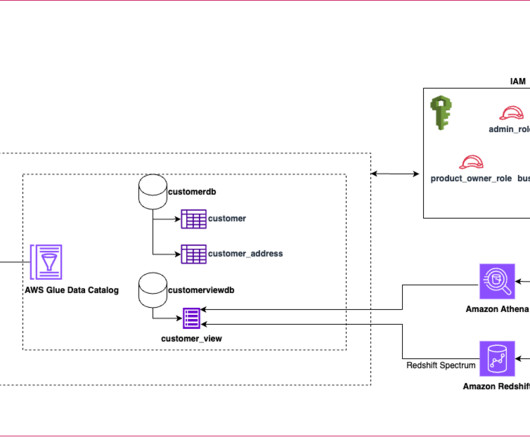
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
For NoSQL, datalakes, and datalake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. Data Modeling.
That said, in this article, we will go through both agile analytics and BI starting from basic definitions, and continuing with methodologies, tips, and tricks to help you implement these processes and give you a clear overview of how to use them. In our opinion, both terms, agile BI and agile analytics, are interchangeable and mean the same.
Use case A typical workload for AWS Glue for Apache Spark jobs is to load data from a relational database to a datalake with SQL-based transformations. The following is a visual representation of an example job where the number of workers is 10. On the Graphed metrics tab, configure your preferred statistic, period, and so on.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. They store their product data in Iceberg format on Amazon S3 and host the metadata of their datasets in Hive Metastore on the EMR primary node. Choose Create.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
As access to and use of data has now expanded to business team members and others, it’s more important than ever that everyone can appreciate what happens to data as it goes through the BI and analytics process. Your definitive guide to data and analytics processes. Data modeling: Create relationships between data.
To fill in the gaps in existing data, HR&A creates digital equity surveys to build a more complete picture before developing digital equity plans. HR&A has used Amazon Redshift Serverless and CARTO to process survey findings more efficiently and create custom interactive dashboards to facilitate understanding of the results.
Import flow definition : by dragging and dropping a process group on the canvas, you can now easily import a flow definition that you exported in another environment. Cloudera commits to provide you with the best options to move data from any system to any other system.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
When setting out to build a data warehouse, it’s a common pattern to have a datalake as the source of the data warehouse. The datalake in this context serves a number of important functions: It acts as a central source for multiple applications, not just exclusively for data warehousing purposes.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI. New insights and relationships are found in this combination. All of this supports the use of AI.
OVO UnCover enables access to real-time customer data using advanced, intelligent data analytics and machine learning to personalize the customer product interaction experience. This enabled Merck KGaA to control and maintain secure data access, and greatly increase business agility for multiple users.
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate datalakes and data warehouses for analytics and machine learning. You can then augment recommendations with out-of-the-box data quality rules.
In this workflow, data is written to Amazon S3 through the Confluent S3 sink connector and then analyzed with Athena, a serverless interactive analytics service that enables you to analyze and query data stored in Amazon S3 and various other data sources using standard SQL. Choose Create data source. Choose Next.
So what is data wrangling? Let’s imagine the process of building a datalake. First off, data wrangling is gathering the appropriate data. Sometimes, you need to re-categorize the past to match up to the current category definitions. You’ve got yourself a little datalake, but its waters are brackish.
On the Crawlers page, select data-quality-result-crawler and choose Run. When the crawler is complete, you can see the AWS Glue Data Catalog table definition. After you create the table definition on the AWS Glue Data Catalog, you can use Athena to query the Data Catalog table.
With Itzik’s wisdom fresh in everyone’s minds, Scott Castle, Sisense General Manager, Data Business, shared his view on the role of modern data teams. Scott whisked us through the history of business intelligence from its first definition in 1958 to the current rise of Big Data. Omid Vahdaty, CTO of Jutomate Ltd.,
The Structured Query Language (SQL) becomes the standardized language for interacting with relational databases. The Entity-Relationship (ER) model gains prominence as a tool for conceptual data modeling, helping to bridge the gap between business requirements and database design.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. A data fabric is comprised of a network of data nodes (e.g.,
To configure AWS CLI interaction with AWS, refer to Quick setup. He is passionate about big data and data analytics. Sandeep Singh is a Lead Consultant at AWS ProServe, focused on analytics, datalake architecture, and implementation. Amol Guldagad is a Data Analytics Consultant based in India.
Any change to the dimension definition results in a lengthy and time-consuming reprocessing of the dimension data, which often results in data redundancy. Another issue is that, when relying merely on dimensional modeling, analysts can’t assure the consistency and accuracy of data sources.
From the Cloudera Management Console, click Data Hub Clusters. Click Create Data Hub. In the Selected Environment with running DataLake drop-down list, select the same environment used by your COD instance. Select the Cluster Definition. For example, select the 7.2.10 COD Edge Node for AWS cluster template.
Prerequisites Before setting up the CloudFormation stacks, you must have an AWS account and an AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and the services listed in the architecture. About the author Sandeep Bajwa is a Sr.
The loose coupling between event publishers and subscribers empowered teams to focus on distinct domains, such as data ingestion, identification services, and datalakes. With Kafka ACLs, we enforced strict access controls, allowing consumers and producers to only interact with authorized topics.
Today, I can provide managers in finance, sales, operations, all the way up to the CEO, with interactive dashboards, intuitive charts, and technical indicators that can be read by non-IT people to describe the health of the systems,” says Deligia. Flexible, automated IT also provides an added benefit in connecting technology and business.
Solution overview For our use case, we use several AWS services to stream, ingest, transform, and analyze sample automotive sensor data in real time using Kinesis Data Analytics Studio. Kinesis Data Analytics Studio allows us to create a notebook, which is a web-based development environment.
This job extracts data from the Kafka topics, deserializes it using the schema information from the Data Catalog table, and loads it into Amazon S3. It’s important to note that the schema in the Data Catalog table serves as the source of truth for the AWS Glue streaming job.
The preceding SparkApplication definition has the event log enabled and stores the events in an S3 bucket with the following path: s3://YOUR-S3-BUCKET/. buffer.dir=/mnt/s3 --conf spark.hadoop.fs.s3n.impl=com.amazon.ws.emr.hadoop.fs.EmrFileSystem --deploy-mode cluster s3://aws-data-lake-workshop/spark-eks/spark-eks-assembly-3.3.0.jar
With AWS Glue, you can discover and connect to hundreds of different data sources and manage your data in a centralized data catalog. You can visually create, run, and monitor ETL pipelines to load data into your datalakes. Complete the following scripts to create the DAG: Create a local file named emr_dag.py
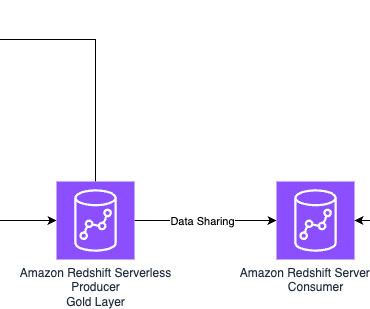
DSF provides convenient methods for the end-to-end flow for both data producer and consumer. Solution overview The solution demonstrates a common pattern where a data warehouse is used as a serving layer for business intelligence (BI) workloads on top of datalakedata. No schema is needed.
Look toward the evolving changes in system architecture to understand where data governance will be heading. Definition and Descriptions. We’ll start with standard definitions – the currently accepted wisdom in the industry. That definition plus the one-liner provide good starting points. In other words, #adulting.
The definitive three rings. I concluded I could finally produce a toolkit with our definitive three rings advice; including the advanced stuff mentioned above. Here is my final analysis of my 1-1s and interactions this week: Topic: Data Governance 28. Vision/Data Driven/Outcomes 28. Datalake 4.
The first and most important thing to recognize and understand is the new and radically different target environment that you are now designing a data model for. Star schema: a data modeling and database design paradigm for data warehouses and datalakes. Are you ready to try out the newest erwin Data Modeler?
Let’s start however with some definitions. A number of factors can play into the accuracy of data capture. Some systems (even in 2018) can still make it harder to capture good data than to ram in bad. Here I will look to cover some of the obstacles and suggest a potential way to navigate round them. Oxford Dictionaries ).
A useful feature for exposing patterns in the data. Supports the ability to interact with the actual data and perform analysis on it. For example, data science always consumes “historical” data, and there is no guarantee that the semantics of older datasets are the same, even if their names are unchanged.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content