

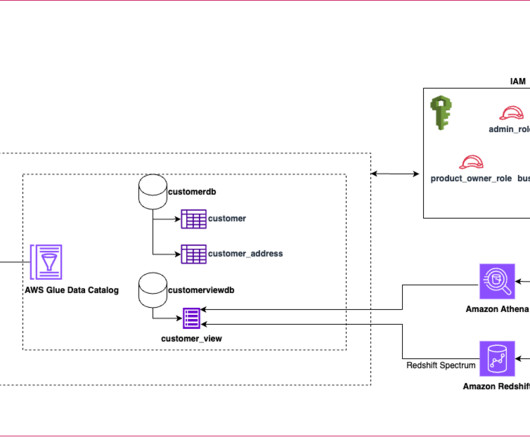
How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
When evolving such a partition definition, the data in the table prior to the change is unaffected, as is its metadata. Only data that is written to the table after the evolution is partitioned with the new definition, and the metadata for this new set of data is kept separately.


















































Let's personalize your content