This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. Delete the bucket.
Rapidminer is a visual enterprisedata science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.
For context, read this perspective by my colleague, Matt Aslett, on the importance of local data processing. Our research shows that more than half of enterprises (58%) have the majority of data platforms in the cloud, but a substantial portion is deployed on premises. Regards, David Menninger
From within the unified studio, you can discover data and AI assets from across your organization, then work together in projects to securely build and share analytics and AI artifacts, including data, models, and generative AI applications.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
With the core architectural backbone of the airlines gen AI roadmap in place, including United Data Hub and an AI and ML platform dubbed Mars, Birnbaum has released a handful of models into production use for employees and customers alike. That number has increased to 21% in just 18 months.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. This is where Amazon Bedrock comes into play.
The rise of generative AI (GenAI) felt like a watershed moment for enterprises looking to drive exponential growth with its transformative potential. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
While new and emerging capabilities might catch the eye, features that address data platform security, performance and availability remain some of the most significant deal-breakers when enterprises are considering potential data platform providers. This is especially true for mission-critical workloads. Regards, Matt Aslett
A high hurdle many enterprises have yet to overcome is accessing mainframe data via the cloud. Data professionals need to access and work with this information for businesses to run efficiently, and to make strategic forecasting decisions through AI-powered datamodels.
Why should you integrate data governance (DG) and enterprise architecture (EA)? Two of the biggest challenges in creating a successful enterprise architecture initiative are: collecting accurate information on application ecosystems and maintaining the information as application ecosystems change.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
DataOps adoption continues to expand as a perfect storm of social, economic, and technological factors drive enterprises to invest in process-driven innovation. In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Data Gets Meshier.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Ostensibly, the new product represents Microsoft’s transition to a newer, more cloud-friendly ERP for midsized enterprises. That stands for “bring your own database,” and it refers to a model in which core ERP data are replicated to a separate standalone database used exclusively for reporting. Option 3: Azure DataLakes.
Enterprisedata is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. foundation model (FM) in Amazon Bedrock as the LLM. The answer is yes.
The data mesh design pattern breaks giant, monolithic enterprisedata architectures into subsystems or domains, each managed by a dedicated team. But first, let’s define the data mesh design pattern. The past decades of enterprisedata platform architectures can be summarized in 69 words.
This evaluation, we feel, critically examines vendors capabilities to address key service needs, including data engineering, operational data integration, modern data architecture delivery, and enabling less-technical data integration across various deployment models.
Data mesh and DataOps provide the organization, enterprise architecture, and workflow automation that together enable a relatively small data team to address the analytics needs of hundreds of active business users. Figure 1: Data requirements for phases of the drug product lifecycle. The new Recipes run, and BOOM!
One-time and complex queries are two common scenarios in enterprisedata analytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Here, datamodeling uses dbt on Amazon Redshift.
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
Between building gen AI features into almost every enterprise tool it offers, adding the most popular gen AI developer tool to GitHub — GitHub Copilot is already bigger than GitHub when Microsoft bought it — and running the cloud powering OpenAI, Microsoft has taken a commanding lead in enterprise gen AI. That’s risky.”
Data must be laboriously collected, curated, and labeled with task-specific annotations to train AI models. Building a model requires specialized, hard-to-find skills — and each new task requires repeating the process. ” These large models have lowered the cost and labor involved in automation.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
When building a machine-learning-powered tool to predict the maintenance needs of its customers, Ensono found that its customers used multiple old apps to collect incident tickets, but those apps stored incident data in very different formats, with inconsistent types of data collected, he says.
Developers can rapidly implement sophisticated data querying features without complex codingjust connect to the API endpoints and let users explore financial data using plain English. Enable Amazon Bedrock large language model (LLM) access for Amazon Nova Pro. Choose Enable specific models. Choose Test.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. The new category is often called MLOps. Compute.
I aim to outline pragmatic strategies to elevate data quality into an enterprise-wide capability. Key recommendations include investing in AI-powered cleansing tools and adopting federated governance models that empower domains while ensuring enterprise alignment. The patterns are consistent across industries.
In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations. A distributed data mesh is a better choice. The book will be available from O’Reilly Media here.
AI is now a board-level priority Last year, AI consisted of point solutions and niche applications that used ML to predict behaviors, find patterns, and spot anomalies in carefully curated data sets. Today’s foundational models are jacks-of-all-trades. All of PwC’s clients are having this discussion, he says. Gen AI took a few months.
Count TransUnion among the rising tide of enterprises evolving their identities thanks to IT. “We The power of productizing data TransUnion’s OneTru has been made possible by the company’s migration to AWS, dubbed “Project Rise,” which is slated for completion by year’s end.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Scalability ABAC systems are more scalable for larger enterprises because they can handle a large number of users and resources without requiring a large number of roles. Attribute-based access control overview Previously, within SageMaker Lakehouse, Lake Formation granted access to resources based on the identity of a requesting user.
From IT, to finance, marketing, engineering, and more, AI advances are causing enterprises to re-evaluate their traditional approaches to unlock the transformative potential of AI. What can enterprises learn from these trends, and what future enterprise developments can we expect around generative AI?
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. Data labeling is required for various use cases, including forecasting, computer vision, natural language processing, and speech recognition.
Under the federated mesh architecture, each divisional mesh functions as a node within the broader enterprisedata mesh, maintaining a degree of autonomy in managing its data products. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
This year, however, Salesforce has accelerated its agenda, integrating much of its recent work with large language models (LLMs) and machine learning into a low-code tool called Einstein 1 Studio. Einstein 1 Studio is a set of low-code tools to create, customize, and embed AI models in Salesforce workflows. What is Einstein 1 Studio?
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
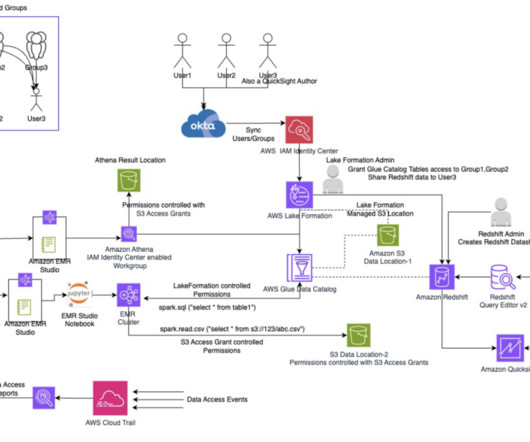
Many organizations use external identity providers (IdPs) such as Okta or Microsoft Azure Active Directory to manage their enterprise user identities. Later in this post, we also briefly touch upon using CloudTrail Lake to query the data access events. In the following sections, we demonstrate how to build this architecture.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content