This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. The sample files are ‘|’ delimited text files.
For context, read this perspective by my colleague, Matt Aslett, on the importance of local data processing. Our research shows that more than half of enterprises (58%) have the majority of data platforms in the cloud, but a substantial portion is deployed on premises. Regards, David Menninger
DataOps adoption continues to expand as a perfect storm of social, economic, and technological factors drive enterprises to invest in process-driven innovation. In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Data Gets Meshier.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more. Choose Test connection.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. We recommend testing your use case and data with different models.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. The open table format accelerates companies’ adoption of a modern data strategy because it allows them to use various tools on top of a single copy of the data.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Data mesh and DataOps provide the organization, enterprise architecture, and workflow automation that together enable a relatively small data team to address the analytics needs of hundreds of active business users. Figure 1: Data requirements for phases of the drug product lifecycle. The new Recipes run, and BOOM!
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. . The challenge is that data engineering and analytics are incredibly complex. The data requirements of a thriving business are never complete.
The data mesh design pattern breaks giant, monolithic enterprisedata architectures into subsystems or domains, each managed by a dedicated team. But first, let’s define the data mesh design pattern. The past decades of enterprisedata platform architectures can be summarized in 69 words.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. An Overarching Concern: Correctness and Testing. Why did something break?
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Amazon DataZone recently announced the expansion of data analysis and visualization options for your project-subscribed data within Amazon DataZone using the Amazon Athena JDBC driver. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. Follow him on LinkedIn.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
Lack of clear, unified, and scaled data engineering expertise to enable the power of AI at enterprise scale. Some of the work is very foundational, such as building an enterprisedatalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service.
There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes. There has been a lot of talk over the past year or two in the D365F&SCM world about “datalakes.” Traditional databases and data warehouses do not lend themselves to that task.
When you build your transactional datalake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 datalake to optimize the production environment. Jupyter Enterprise Gateway 2.6.0, availability. This example is demonstrated on an EMR version emr-6.10.0
The data analytics function in large enterprises is generally distributed across departments and roles. For example, teams working under the VP/Directors of Data Analytics may be tasked with accessing data, building databases, integrating data, and producing reports. Analytics Hub and Spoke. DataOps Process Hub.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising data integrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
Since 2015, the Cloudera DataFlow team has been helping the largest enterprise organizations in the world adopt Apache NiFi as their enterprise standard data movement tool. What is the modern data stack? In the modern data stack, there is a diverse set of destinations where data needs to be delivered.
Your Chance: Want to test an agile business intelligence solution? It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. Finalize testing. Train end-users.
DataOps has become an essential methodology in pharmaceutical enterprisedata organizations, especially for commercial operations. Companies that implement it well derive significant competitive advantage from their superior ability to manage and create value from data. Has the data arrived on time?
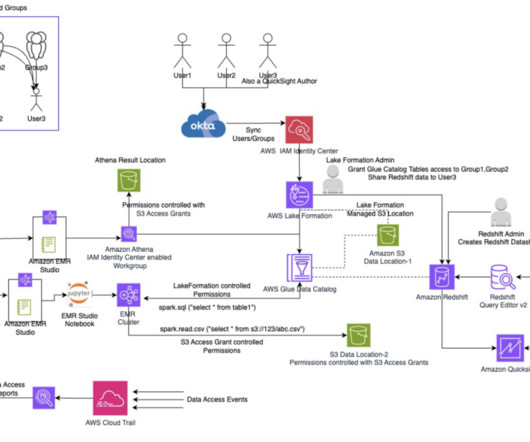
Many organizations use external identity providers (IdPs) such as Okta or Microsoft Azure Active Directory to manage their enterprise user identities. Provide a database name ( tip-blog-redshift-ds-db ), which will be created in the Data Catalog by Lake Formation. In this post, we grant access to Group1.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Enterprisedata is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. A question arises on what level of details we need to include in the table metadata.
I aim to outline pragmatic strategies to elevate data quality into an enterprise-wide capability. Key recommendations include investing in AI-powered cleansing tools and adopting federated governance models that empower domains while ensuring enterprise alignment. Inflexible schema, poor for unstructured or real-time data.
Generative AI touches every aspect of the enterprise, and every aspect of society,” says Bret Greenstein, partner and leader of the gen AI go-to-market strategy at PricewaterhouseCoopers. Gen AI is that amplification and the world’s reaction to it is like enterprises and society reacting to the introduction of a foreign body. “We
Since 2015, the Cloudera DataFlow team has been helping the largest enterprise organizations in the world adopt Apache NiFi as their enterprise standard data movement tool. What is the modern data stack? In the modern data stack, there is a diverse set of destinations where data needs to be delivered.
Testing these upgrades involves running the application and addressing issues as they arise. Each test run may reveal new problems, resulting in multiple iterations of changes. They then need to modify their Spark scripts and configurations, updating features, connectors, and library dependencies as needed. Python 3.7) to Spark 3.3.0
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
Today, more than 90% of its applications run in the cloud, with most of its data is housed and analyzed in a homegrown enterprisedata warehouse. Like many CIOs, Carhartt’s top digital leader is aware that data is the key to making advanced technologies work. Today, we backflush our datalake through our data warehouse.
By using automated and repeatable capabilities, you can quickly and safely migrate data to the cloud and govern it along the way. But transforming and migrating enterprisedata to the cloud is only half the story – once there, it needs to be governed for completeness and compliance. GDPR, CCPA, HIPAA, SOX, PIC DSS).
Terminology Let’s first discuss some of the terminology used in this post: Research datalake on Amazon S3 – A datalake is a large, centralized repository that allows you to manage all your structured and unstructured data at any scale.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
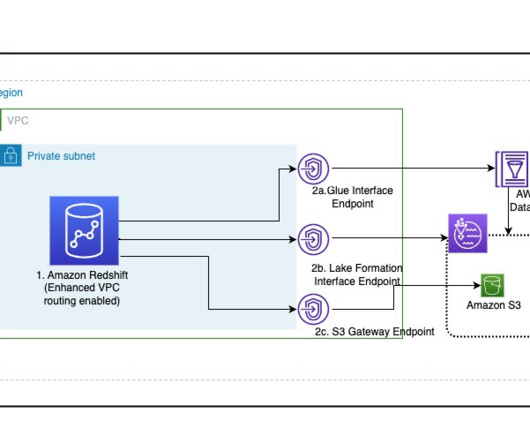
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content