This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
data engineers delivered over 100 lines of code and 1.5 data quality tests every day to support a cast of analysts and customers. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. The TICKIT dataset records sales activities on the fictional TICKIT website, where users can purchase and sell tickets online for different types of events such as sports games, shows, and concerts.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Amazon S3 emits an object created event and matches an EventBridge rule.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising data integrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
Datalakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a datalake design, data should be immutable once stored. A datalake built on AWS uses Amazon Simple Storage Service (Amazon S3) as its primary storage environment.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
It also helps you to securely access your data in operational databases, datalakes or third-party datasets with minimal movement or copying. Amazon S3 Event Notifications is an Amazon S3 feature that you can enable in order to receive notifications when specific events occur in your S3 bucket.
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 datalakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) datalake that is using the Apache Iceberg open table format and running on the Amazon EMR big data platform.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
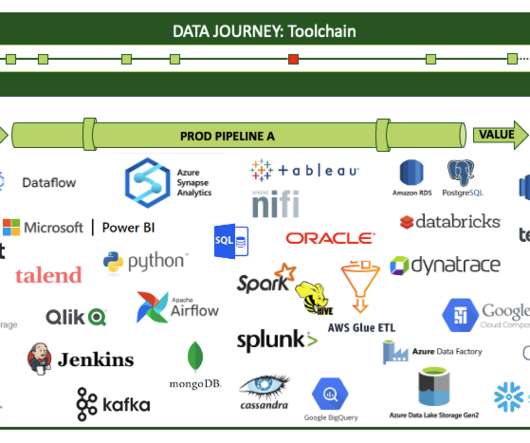
As he thinks through the various journeys that data take in his company, Jason sees that his dashboard idea would require extracting or testing for events along the way. So, the only way for a data journey to truly observe what’s happening is to get his tools and pipelines to auto-report events.
Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built datalake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire organization.
The data engineer then emails the BI Team, who refreshes a Tableau dashboard. Figure 1: Example data pipeline with manual processes. There are no automated tests , so errors frequently pass through the pipeline. Figure 2: Example data pipeline with DataOps automation. Adding Tests to Reduce Stress.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
Terminology Let’s first discuss some of the terminology used in this post: Research datalake on Amazon S3 – A datalake is a large, centralized repository that allows you to manage all your structured and unstructured data at any scale.
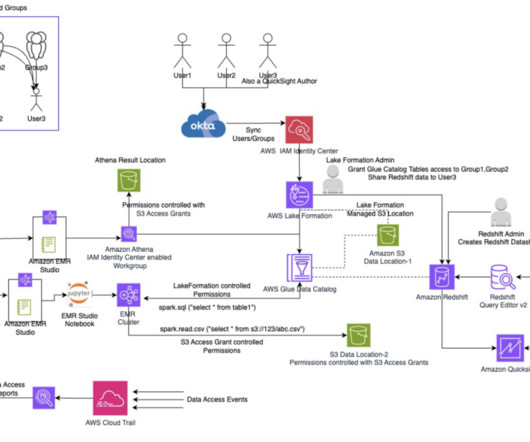
To enable access control with Lake Formation for Redshift tables, we use data sharing in Lake Formation. Data access requests by the specific users are logged to CloudTrail. Later in this post, we also briefly touch upon using CloudTrail Lake to query the data access events.
Unlike many other events, which consist of multiple racing teams and manufacturers, Porsche Carrera Cup Brasil provides and maintains all 75 cars used in the race. If I don’t do predictive maintenance, if I have to do corrective maintenance at events, a lot of money is wasted.”
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Data warehouse Centralized, structured and curated data repository. Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructured data.
Due to these limitations, the application should not be used for arbitrary tests. In this post, we provide instructions on how to deploy a sample API application integrated with Lake Formation that implements the solution architecture. We also show how to test the function with Lambda tests.
With automated alerting with a third-party service like PagerDuty , an incident management platform, combined with the robust and powerful alerting plugin provided by OpenSearch Service, businesses can proactively manage and respond to critical events. Leave the defaults and choose Next.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Apache Hudi supports ACID transactions and CRUD operations on a datalake. You don’t alter queries separately in the datalake.
The integration is new way for customers to query operational logs in Amazon S3 and Amazon S3-based datalakes without needing to switch between tools to analyze operational data. Amazon S3 is an object storage service offering industry-leading scalability, data availability, security, and performance.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
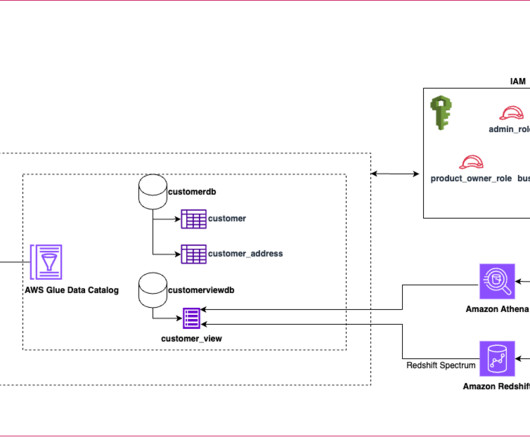
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
To access data in real time — and ensure that it provides actionable insights for all stakeholders — organizations should invest in the foundational components that enable more efficient, scalable, and secure data collection, processing, and analysis. Nichol ( @PeterBNichol ), Chief Technology Officer at OROCA Innovations. “The
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
The biggest challenge for any big enterprise is organizing the data that has organically grown across the organization over the last several years. Everyone has datalakes, data ponds – whatever you want to call them. How do you get your arms around all the data you have? This isn’t unique to Verizon.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
You might be modernizing your data architecture using Amazon Redshift to enable access to your datalake and data in your data warehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. For IAM role , choose a Lake Formation user-defined role.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content