This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As part of its storytelling ethos, the flight-status LLM will specify, for example, which precise weather event may be affecting a delayed flight and provide quick and useful information to customers about next actions.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructureddata. For a table that will be converted, it invokes the converter Lambda function through an event.
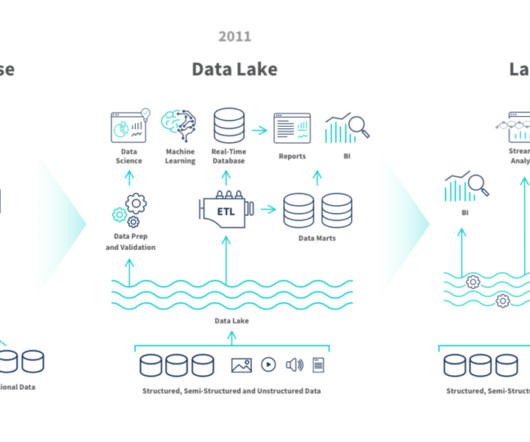
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructureddata. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
Different types of information are more suited to being stored in a structured or unstructured format. Read on to explore more about structured vs unstructureddata, why the difference between structured and unstructureddata matters, and how cloud data warehouses deal with them both. Unstructureddata.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructureddata, most enterprises manage and deliver data to the datalake and leverage various applications like ETL tools, search engines, and databases for analysis.
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed. Sharing Customer 360 insights back without data replication. Currently, Data Cloud leverages live SQL queries to access data from external data platforms via zero copy.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
For example, in a chatbot, dataevents could pertain to an inventory of flights and hotels or price changes that are constantly ingested to a streaming storage engine. Furthermore, dataevents are filtered, enriched, and transformed to a consumable format using a stream processor.
Azure Data Explorer is used to store and query data in services such as Microsoft Purview, Microsoft Defender for Endpoint, Microsoft Sentinel, and Log Analytics in Azure Monitor. Azure DataLake Analytics. Data warehouses are designed for questions you already know you want to ask about your data, again and again.
Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructureddata. Low cost, flexibility, captures diverse data sources. Easy to lose control, risk of becoming a data swamp. Exploratory analytics, raw and diverse data types.
Terminology Let’s first discuss some of the terminology used in this post: Research datalake on Amazon S3 – A datalake is a large, centralized repository that allows you to manage all your structured and unstructureddata at any scale. This is where the tagging feature in Apache Iceberg comes in handy.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
The only thing we have on premise, I believe, is a data server with a bunch of unstructureddata on it for our legal team,” says Grady Ligon, who was named Re/Max’s first CIO in October 2022. Finally, the IT team developed a digital market center that offers event management as well as training and education content.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructureddata. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Scope could be: Data (i.e. Information (processed data). Records (files, or what you might all unstructureddata). Events or transactions. Analytical stewardship is a missing link in analytics, BI and data science. Downstream in the analytics pipeline. Analytic (the analytics itself). Images (i.e.
Data science is an area of expertise that combines many disciplines such as mathematics, computer science, software engineering and statistics. It focuses on data collection and management of large-scale structured and unstructureddata for various academic and business applications.
July brings summer vacations, holiday gatherings, and for the first time in two years, the return of the Massachusetts Institute of Technology (MIT) Chief Data Officer symposium as an in-person event. A key area of focus for the symposium this year was the design and deployment of modern data platforms.
The alleviation of infrastructure and computational constraints associated with solely on-premises data platforms; Data Products can now use different deployment models (e.g., The proliferation of real-time processing by deploying event-driven architectures (e.g., data warehousing). Deep Java Learning, Apache Spark 3.x,
By adopting a custom developed application based on the Cloudera ecosystem, Carrefour has combined the legacy systems into one platform which provides access to customer data in a single datalake. transactions per day and processing information at a rate of 1k events per second. Cloud Innovation.
To drive this point home, Yonatan Dolan, an Analytics Specialist from AWS, introduced AWS’ new Lake House architecture. This cutting-edge service integrates the abilities of a datalake, a data warehouse, and purpose-built stores, to enable unified governance and easy data movement.
This approach also relates to monitoring internal fiduciary risk by tying separate events together, such as a large position (relative to historic norms) being taken immediately after the risk model that would have flagged it was modified in a separate system. Market data: Coordinated trading among multiple parties.
At the heart of all data warehousing is integration, and this layer contains integrated data from multiple sources built around the enterprise-wide business keys. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse.
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructureddata. In that sense, data modernization is synonymous with cloud migration. Efficient Data Processing. Enhanced Accessibility.
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021!
Today transactional data is the largest segment, which includes streaming and data flows. EXTRACTING VALUE FROM DATA. One of the biggest challenges presented by having massive volumes of disparate unstructureddata is extracting useable information and insights.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Continued global digitalization is creating huge quantities of data for modern organizations. To have any hope of generating value from growing data sets, enterprise organizations must turn to the latest technology. Since then, technology has improved in leaps and bounds and data management has become more complicated.
Trino allows users to run ad hoc queries across massive datasets, making real-time decision-making a reality without needing extensive data transformations. This is particularly valuable for teams that require instant answers from their data. DataLake Analytics: Trino doesn’t just stop at databases. Privacy Policy.
Over time, the worlds of datalakes and data warehouses collided. Databricks introduced the concept of a data lakehouse , adding Databricks SQL as well as open table formats. Databricks was also rated Exemplary in our Data Intelligence , Data Integration and Data Governance Buyers Guides.
In addition to technical advancements, the event highlighted strategic initiatives that resonate with CIOs, including cost optimization, workflow efficiency, and accelerated AI application development. AWSs annual re:Invent developer conference concluded last week.
Real-time data integration at scale Real-time data integration is crucial for businesses like e-commerce and finance, where speed is critical. In the years to come, advancements in event-driven architectures and technologies like change data capture (CDC) will enable seamless data synchronization across systems with minimal lag.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content