This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. The post DataLake or Data Warehouse- Which is Better?
A datalake is a centralized repository designed to house big data in structured, semi-structured and unstructured form. I have been covering the datalake topic for several years and encourage you to check out an earlier perspective called DataLakes: Safe Way to Swim in Big Data?
Everyone talks about data quality, as they should. Our research shows that improving the quality of information is the top benefit of data preparation activities. Data quality efforts are focused on clean data. Yes, clean data is important. but so is bad data.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and data warehouse capabilities are required to leverage this data.
Data architectures to support reporting, business intelligence, and analytics have evolved dramatically over the past 10 years. Download this TDWI Checklist report to understand: How your organization can make this transition to a modernized data architecture.
Some of these are emerging topics and others are developments on existing concepts, but all of them will inform our thinking in the coming year. The Right Solution for Your Data: Cloud DataLakes and Data Lakehouses. A Wave of Cloud-Native, Distributed Data Frameworks.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. Upload the data file to the S3 bucket created by the CloudFormation stack.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback.
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a DataLake implemented with cloud storage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern data architectures.
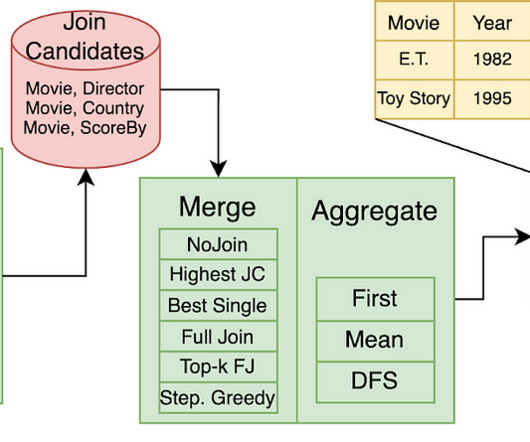
In this series of blog posts, we have been exploring the problem of augmenting a table using information contained in a datalake (a large collection of datasets).
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Chief among these is United ChatGPT for secure employee experimental use and an external-facing LLM that better informs customers about flight delays, known as Every Flight Has a Story, that has already boosted customer satisfaction by 6%, Birnbaum notes. Historically United storytellers had to manually edit templates, which took time.
With the exponential growth of data, companies are handling huge volumes and a wide variety of data including personally identifiable information (PII). PII is a legal term pertaining to information that can identify, contact, or locate a single person. For our solution, we use Amazon Redshift to store the data.
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications.
The company added support for vector search in 2023, which can help organizations improve trust in the output of GenAI by providing access to factually accurate and up-to-date information.
Prerequisites To follow the steps in this post, you must complete the following prerequisites: AWS account with access to the following AWS services: Amazon S3 AWS Lake Formation and AWS Glue Data Catalog Amazon Redshift Amazon Athena Amazon EMR AWS Identity and Access Management (IAM) Set up an admin user for Ava. Choose Grant.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Its data intelligence cloud platform can automatically classify data from various sources such as online transaction processing databases, master repositories and Excel files without moving the data, so the information assets stay protected.
This allows for the extraction and integration of data into AI models without overhauling entire platforms, Erolin says. CIOs should also use datalakes to aggregate information from multiple sources, he adds. AI models can then access the data they need without direct reliance on outdated apps.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs. Refer to AWS Glue job parameters for more details.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Can it also help write SQL queries? The answer is yes.
In the context of comprehensive data governance, Amazon DataZone offers organization-wide data lineage visualization using Amazon Web Services (AWS) services, while dbt provides project-level lineage through model analysis and supports cross-project integration between datalakes and warehouses. hasLabel('lineage_node').outE('lineage_edge').inV().hasLabel('lineage_node').path().by(elementMap())
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) datalakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. By providing a standardized framework for data representation, open table formats break down data silos, enhance data quality, and accelerate analytics at scale.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. They would like to get a cross-organization visibility of supply chain and inventory data.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content