This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
In order to help maintain data privacy while validating and standardizing data for use, the IDMC platform offers a Data Quality Accelerator for Crisis Response. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. Data that needs to be tightly controlled (e.g. The Problem with Hybrid Cloud Environments.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
That was the Science, here comes the Technology… A Brief Hydrology of DataLakes. Overlapping with the above, from around 2012, I began to get involved in also designing and implementing Big Data Architectures; initially for narrow purposes and later DataLakes spanning entire enterprises.
In parallel, the Pinot controller tracks the metadata of the cluster and performs actions required to keep the cluster in an ideal state. Its primary function is to orchestrate cluster resources as well as manage connections between resources within the cluster and data sources outside of it.
At the heart of all data warehousing is integration, and this layer contains integrated data from multiple sources built around the enterprise-wide business keys. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
In 2013 I joined American Family Insurance as a metadata analyst. I had always been fascinated by how people find, organize, and access information, so a metadata management role after school was a natural choice. The use cases for metadata are boundless, offering opportunities for innovation in every sector.
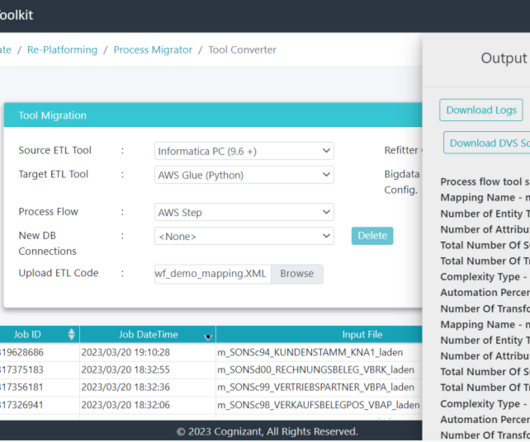
User inputs are stored in the internal metadata repository of the tool and Cognizant Data & Intelligence Toolkit (CDIT): ETL Conversion Tool parses these XML input files and breaks them down to a patented canonical model, which is then forward engineered into the target AWS Glue scripts in Python or Scala.
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. Easy to use, integrated data console: Bring your own data and stay in control of your data.
The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. For governance and security teams, the questions revolve around chain of custody, audit, metadata, access control, and lineage. Without context, streaming data is useless.”
As such banking, finance, insurance and media are good examples of information-based industries compared to manufacturing, retail, and so on. Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? Datalakes don’t offer this nor should they.
Increasingly, Chief Data Officers (CDOs) are the leaders tasked with harnessing data to drive the business forward. Initially, CDOs were funded to ensure compliance in industries like banking, finance, insurance, healthcare and government. Today, the scope of the CDO is shifting toward empowering data-driven organizations.
StarTrees automatic data ingestion framework is ideal for enterprise workloads because it improves scalability and reduces the data maintenance complexity often found in open source Pinot deployments. The data is then modelled to help you organize and structure the data fetched from the selected data source into Pinot tables.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content