This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. In the long run, we see a steep increase in the proliferation of all types of data due to IoT which will pose both challenges and opportunities.
Azure Data Explorer is used to store and query data in services such as Microsoft Purview, Microsoft Defender for Endpoint, Microsoft Sentinel, and Log Analytics in Azure Monitor. Azure DataLake Analytics. Data warehouses are designed for questions you already know you want to ask about your data, again and again.
From origin through all points of consumption both on-prem and in the cloud, all data flows need to be controlled in a simple, secure, universal, scalable, and cost-effective way. controlling distribution while also allowing the freedom and flexibility to deliver the data to different services is more critical than ever. .
The company is also refining its data analytics operations, and it is deploying advanced manufacturing using IoT devices, as well as AI-enhanced robotics. We expect within the next three years, the majority of our applications will be moved to the cloud.”
If this sounds intense, that’s because companies of all shapes and sizes who don’t reckon with the trends changing the data world will be in trouble. Trends Changing Big Data. First off, IoT, the Internet of Things. The IoT is everywhere and there are more pieces of technology connected to it every day. are all things.
Gartner defines dark data as “The information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes (for example, analytics, business relationships and direct monetizing).”
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
Solution overview For our use case, we use several AWS services to stream, ingest, transform, and analyze sample automotive sensor data in real time using Kinesis Data Analytics Studio. Kinesis Data Analytics Studio allows us to create a notebook, which is a web-based development environment. Choose Next. Choose Create stack.
Facing a constant onslaught of cost pressures, supply chain volatility and disruptive technologies like 3D printing and IoT. Or we create a datalake, which quickly degenerates to a data swamp. Coupled with search and multi-modal interaction, gen AI makes a great assistant.
To do this Manulife’s in-house data team built an Enterprise DataLake (EDL) — a robust, enterprise-wide, data backend supporting digital connection, report automation, and AI & advanced analytics development. They wanted a holistic view of their customers, in order to provide better services.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
We created a datalake, so we have access to all that data in a very efficient way,” says Papermaster. We look at the data to find out where there’s a yield improvement based on interactions of our design with the manufacturing.” That information is now stored in a way that makes it useable to different tools. “We
Each client and vendor I have interacted with is the beginning of a lifelong professional relationship. And each colleague I interact with is the beginning of a lifelong friendship. Like the Big Apple, data is a topic that never sleeps. Somehow the data deluge barely leaves enough oxygen for a social media dopamine fix!
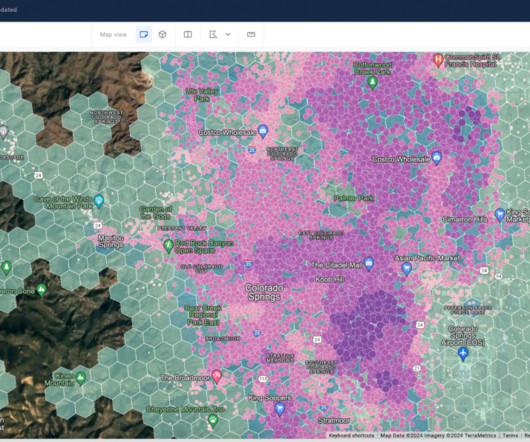
However, visualizing and analyzing large-scale geospatial data presents a formidable challenge due to the sheer volume and intricacy of information. The need to balance detail and context while maintaining real-time interactivity can lead to issues of scalability and rendering complexity.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. A data fabric is comprised of a network of data nodes (e.g.,
Soon after, we announced the release of Sisense Hunch which provides the ability to transform even the most massive data sets into a deep neural net which can be placed anywhere, even on an IoT device. Data literacy and data skills, which created the forgotten dark datalakes in the first place, are still scarce.
Ten years ago, we launched Amazon Kinesis Data Streams , the first cloud-native serverless streaming data service, to serve as the backbone for companies, to move data across system boundaries, breaking data silos. Real-time streaming data technologies are essential for digital transformation.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. Vijay Bagur is a Sr.
At the heart of all data warehousing is integration, and this layer contains integrated data from multiple sources built around the enterprise-wide business keys. Although datalakes resemble data vaults, a data vault provides more features of a data warehouse. What is a hybrid model?
Now, with processing power built out at the edge and with mounting demand for real-time insights, organizations are using decentralized data strategies to drive value and realize business outcomes. billion connected Internet of Things (IoT) devices by 2025, generating almost 80 billion zettabytes of data at the edge.
Here is my final analysis of my 1-1s and interactions this week: Topic: Data Governance 28. Vision/Data Driven/Outcomes 28. Data, analytics, or D&A Strategy 21. Modern) Master Data Management 18. Datalake 4. Data Literacy 4. IoT/Streaming data 1. AI/Automation 6.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected. The following diagram illustrates our solution architecture.
Similary, every touchpoint offers data that can help you improve that customer experience, from the number and duration of support interactions to the intuitiveness of your website. Analyzing this data can build your ability to anticipate a customer’s specific needs. But customers aren’t data; they’re people.
Every user can now create interactive reports and utilize data visualization to disseminate knowledge to both internal and external stakeholders. BI dashboards typically display a variety of data visualizations to give users a comprehensive view of relevant KPIs and trends for both strategic planning and operational decision-making.
A useful feature for exposing patterns in the data. Supports the ability to interact with the actual data and perform analysis on it. For example, data science always consumes “historical” data, and there is no guarantee that the semantics of older datasets are the same, even if their names are unchanged.
To answer these questions we need to look at how data roles within the job market have evolved, and how academic programs have changed to meet new workforce demands. In the 2010s, the growing scope of the data landscape gave rise to a new profession: the data scientist. Supporting the next data-literate generation.
And it’s become a hyper-competitive business, so enhancing customer service through data is critical for maintaining customer loyalty. And more recently, we have also seen innovation with IOT (Internet Of Things). In data-driven organizations, data is flowing.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Datalakes were originally designed to store large volumes of raw, unstructured, or semi-structured data at a low cost, primarily serving big data and analytics use cases. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance.
If you reflect for a moment, the last major technology inflection points were probably things like mobility, IoT, development operations and the cloud to name but a few. We havent really seen one in a while that fundamentally changed our thinking about the art of the possible given the demands of the practical.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content