This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Presto is an open source distributed SQL query engine for data analytics and the data lakehouse, designed for running interactive analytic queries against datasets of all sizes, from gigabytes to petabytes. Uber understood that digital superiority required the capture of all their transactional data, not just a sampling.
For NoSQL, datalakes, and datalake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. Data Modeling.
A key pillar of AWS’s modern data strategy is the use of purpose-built data stores for specific use cases to achieve performance, cost, and scale. Deriving business insights by identifying year-on-year sales growth is an example of an online analytical processing (OLAP) query. To house our data, we need to define a data model.
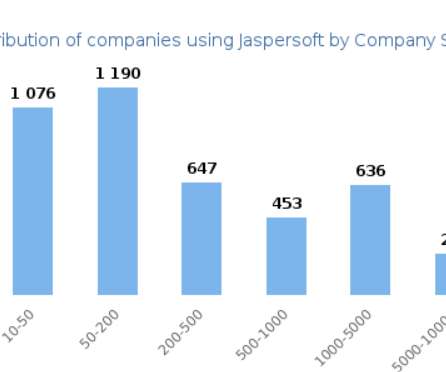
TIBCO Jaspersoft offers a complete BI suite that includes reporting, online analytical processing (OLAP), visual analytics , and data integration. The web-scale platform enables users to share interactive dashboards and data from a single page with individuals across the enterprise. Online Analytical Processing (OLAP).
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
While the architecture of traditional data warehouses and cloud data warehouses does differ, the ways in which data professionals interact with them (via SQL or SQL-like languages) is roughly the same. The primary differentiator is the data workload they serve.
The data warehouse is highly business critical with minimal allowable downtime. We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. Vijay Bagur is a Sr. Technical Account Manager.
The term “ business intelligence ” (BI) has been in common use for several decades now, referring initially to the OLAP systems that drew largely upon pre-processed information stored in data warehouses. Sales and customer service interactions are tracked in CRM.
Although these batch analytics-based efforts were successful to some extent, they saw opportunities to improve the customer experience with real-time personalization and security guidance during the customer’s interaction with the Poshmark app. User interactions on Poshmark web and mobile applications generate server-side events.
The first and most important thing to recognize and understand is the new and radically different target environment that you are now designing a data model for. Star schema: a data modeling and database design paradigm for data warehouses and datalakes. Business Focus. Operational. Operational Tactical.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content