This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
You can navigate to the projects Data page to visually verify the existence of the newly created table. On the top left menu, choose your project name, and under CURRENT PROJECT , choose Data. Additionally, the notebook provides a chart view to visualize query results as graphs. Under Create job , choose Visual ETL.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. In the long run, we see a steep increase in the proliferation of all types of data due to IoT which will pose both challenges and opportunities.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. He is a very visual person, so our proof of concept collects different data sets and ingests them into our Azure data house.
Azure Data Explorer is used to store and query data in services such as Microsoft Purview, Microsoft Defender for Endpoint, Microsoft Sentinel, and Log Analytics in Azure Monitor. Azure DataLake Analytics. Data warehouses are designed for questions you already know you want to ask about your data, again and again.
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Visual Studio Online. This is exactly what it sounds like. Project Silica.
In the subsequent post in our series, we will explore the architectural patterns in building streaming pipelines for real-time BI dashboards, contact center agent, ledger data, personalized real-time recommendation, log analytics, IoTdata, Change Data Capture, and real-time marketing data.
McDermott’s sustainability innovation would not have been possible without key advancements in the cloud, analytics, and, in particular, datalakes, Dave notes. But for Dave, the key ingredient for innovation at McDermott is data. Vagesh Dave. McDermott International. The structures for mining this fuel?
Notebooks are provisioned quickly and provide a way for you to instantly view and analyze your streaming data. This pipeline could further be used to send data to Amazon OpenSearch Service or other targets for additional processing and visualization. To generate the real-time sensor data, we employ the AWS IoT Device Simulator.
Otis One’s cloud-native platform is built on Microsoft Azure and taps into a Snowflake datalake. IoT sensors send elevator data to the cloud platform, where analytics are applied to support business operations, including reporting, datavisualization, and predictive modeling. From the edge to the cloud.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. provides a visual ETL tool for authoring jobs to read from and write to Amazon Redshift, using the Redshift Spark connector for connectivity. AWS Glue 4.0
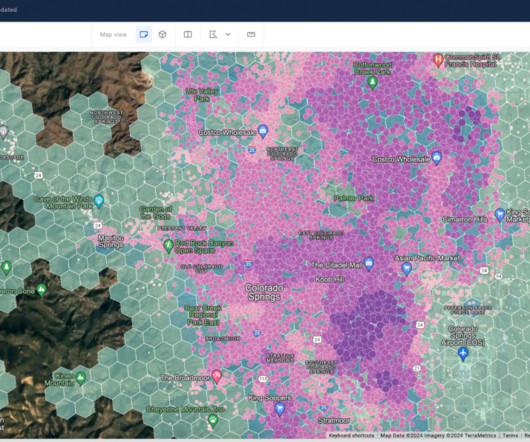
However, visualizing and analyzing large-scale geospatial data presents a formidable challenge due to the sheer volume and intricacy of information. This often overwhelms traditional visualization tools and methods. Figure 1 – Map built with CARTO Builder and the native support to visualize H3 indexes What are spatial indexes?
One of the most promising technology areas in this merger that already had a high growth potential and is poised for even more growth is the Data-in-Motion platform called Hortonworks DataFlow (HDF). CDF, as an end-to-end streaming data platform, emerges as a clear solution for managing data from the edge all the way to the enterprise.
Here are a few examples that we have seen of how this can be done: Batch ETL with Azure Data Factory and Azure Databricks: In this pattern, Azure Data Factory is used to orchestrate and schedule batch ETL processes. Azure Blob Storage serves as the datalake to store raw data.
Here are some of the key use cases: Predictive maintenance: With time series data (sensor data) coming from the equipment, historical maintenance logs, and other contextual data, you can predict how the equipment will behave and when the equipment or a component will fail. Eliminate data silos. That is a very low number.
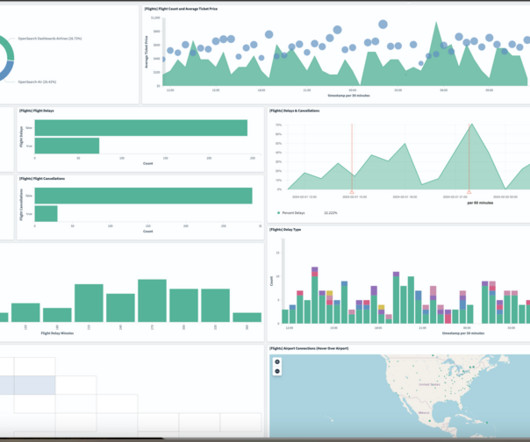
In this post, we dive deep into the tool, walking through all steps from log ingestion, transformation, visualization, and architecture design to calculate TCO. With QuickSight, you can visualize YARN log data and conduct analysis against the datasets generated by pre-built dashboard templates and a widget.
Previously, there were three types of data structures in telco: . Entity data sets — i.e. marketing datalakes . It is an edge-to-AI suite of capabilities, including edge analytics, data staging, data quality control, datavisualization tools, and machine learning.
Soon after, we announced the release of Sisense Hunch which provides the ability to transform even the most massive data sets into a deep neural net which can be placed anywhere, even on an IoT device. Data literacy and data skills, which created the forgotten dark datalakes in the first place, are still scarce.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. Vijay Bagur is a Sr.
Microsoft also releases Power BI, a datavisualization and business intelligence tool. Google launches BigQuery, its own data warehousing tool and Microsoft introduces Azure SQL Data Warehouse and Azure DataLake Store. 2018: IoT and edge computing open up new opportunities for organizations.
Ten years ago, we launched Amazon Kinesis Data Streams , the first cloud-native serverless streaming data service, to serve as the backbone for companies, to move data across system boundaries, breaking data silos. Canva is an online design and visual communication platform.
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021!
Big data architecture is used to augment different applications, operating alongside or in a discrete fashion with a data warehouse. A big data implementation may even replace a data warehouse entirely with a datalake. A modern data warehouse plays a foundational role in analytics and BI.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization.
Every user can now create interactive reports and utilize datavisualization to disseminate knowledge to both internal and external stakeholders. A business intelligence dashboard, also known as a BI dashboard, is a tool that presents important business metrics and data points in a visual and analytical format on a single screen.
A useful feature for exposing patterns in the data. Visual Profiling. Supports the ability to interact with the actual data and perform analysis on it. Pushing data to a datalake and assuming it is ready for use is shortsighted. Parametrization. A technique to automate changes in iterative passes.
Of the prerequisites that follow, the IOT topic rule and the Amazon Managed Streaming for Apache Kafka ( Amazon MSK ) cluster can be set up by following How to integrate AWS IoT Core with Amazon MSK. OpenSearch Ingestion provides a fully managed serverless integration to tap into these data streams.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
For example, for its railway equipment business, Escorts Kubota produces IoT-based devices such as brakes and couplers. How can we make those products smarter by generating a lot of data? This initiative currently uses static data, but Kakkar has bolder ambitions for its agronomic advisory.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content