This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
Introduction You can access your Azure DataLake Storage Gen1 directly with the RapidMiner Studio. This is the feature offered by the Azure DataLake Storage connector. The post Connecting and Reading Data From Azure DataLake appeared first on Analytics Vidhya.
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Speaker: Anthony Roach, Director of Product Management at Tableau Software, and Jeremiah Morrow, Partner Solution Marketing Director at Dremio
As a result, these two solutions come together to deliver: Lightning-fast BI and interactive analytics directly on data wherever it is stored. A self-service platform for data exploration and visualization that broadens access to analytic insights. A seamless and efficient customer experience.
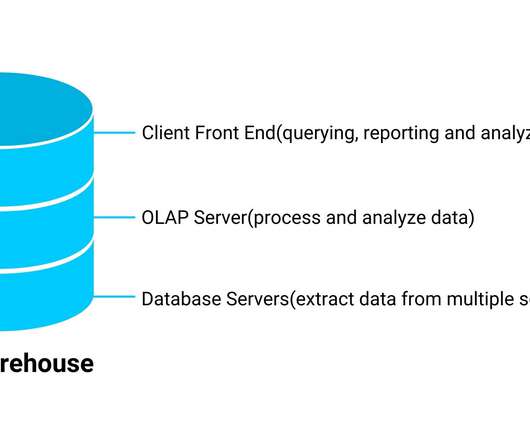
Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better? appeared first on Analytics Vidhya.
Azure DataLake Storage is capable of storing large quantities of structured, semi-structured, and unstructured data in […]. The post Introduction to Azure DataLake Storage Gen2 appeared first on Analytics Vidhya. Introduction ADLS Gen2 The ADLS Gen2 service is built upon Azure Storage as its foundation.
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. However, it also offers additional optimizations that you can use to further improve this performance and achieve even faster query response times from your data warehouse.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
You have lots of data, and you are probably thinking of using the cloud to analyze it. But how will you move data into the cloud? How will you validate and prepare the data? What about streaming data? Can data scientists discover and use the data? Will the datalake scale when you have twice as much data?
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and data warehouse capabilities are required to leverage this data.
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
United claims to be among the earliest users of the Amazon SageMaker ML platform, and it has leveraged its own United Data Hub and AWS Bedrock-based Mars ML platform to create this first batch of production gen AI LLMs. People hear the specifics, and they understand it and their blood pressure goes down.
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
The Right Solution for Your Data: Cloud DataLakes and Data Lakehouses. Datalakes have experienced a fairly robust resurgence over the last few years, specifically cloud datalakes. A Wave of Cloud-Native, Distributed Data Frameworks. Both are seeing strong growth.
Rapidminer is a visual enterprise data science platform that includes data extraction, data mining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Why: Data Makes It Different. In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices?
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Traditional on-premises data processing solutions have led to a hugely complex and expensive set of data silos where IT spends more time managing the infrastructure than extracting value from the data.
We will cover four parts: establishing the infrastructure, getting the data, iterating and automating, and using small, empowered teams. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
It combines SQL analytics, data processing, AI development, data streaming, business intelligence, and search analytics. Another offering that AWS announced to support the integration is the SageMaker Data Lakehouse , aimed at helping enterprises unify data across Amazon S3 datalakes and Amazon Redshift data warehouses.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. This user can query data from any of the cloud stores.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. Why Cloudinary chose Apache Iceberg Apache Iceberg is a high-performance table format for huge analytic workloads.
But collecting data is only half of the equation. As the data grows, it becomes challenging to find the right data at the right time. Many organizations can’t take full advantage of their datalakes because they don’t know what data actually exists.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. Maintaining data consistency and integrity across distributed datalakes is crucial for decision-making and analytics.
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Let’s walk through the architecture chronologically for a closer look at each step.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. This post is co-written with Andries Engelbrecht and Scott Teal from Snowflake.
La firma de consultoría también deberá crear un datalake que permita almacenar y compartir fácilmente los datos de todo el ecosistema deportivo español, para lograr sinergias en torno a los distintos proyectos que se realicen.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
With over 10 PB of data across 1,500 data assets, 1,000 data use cases, and more than 9000 users, the BMW CDH has become a resounding success since BMW decided to build it in a strategic collaboration with Amazon Web Services (AWS) in 2020. This led to inefficiencies in data governance and access control.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content