This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Consultants and developers familiar with the AX data model could query the database using any number of different tools, including a myriad of different report writers. The SQL query language used to extract data for reporting could also potentially be used to insert, update, or delete records from the database.
The magic behind Uber’s data-driven success Uber, the ride-hailing giant, is a household name worldwide. But what most people don’t realize is that behind the scenes, Uber is not just a transportation service; it’s a data and analytics powerhouse.
This approach comes with a heavy computational cost in terms of processing and distributing the data across multiple tables while ensuring the system is ACID-compliant at all times, which can negatively impact performance and scalability. These types of queries are suited for a data warehouse. This is called index overloading.
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. A data hub contains data at multiple levels of granularity and is often not integrated. Data hubs and datalakes can coexist in an organization, complementing each other.
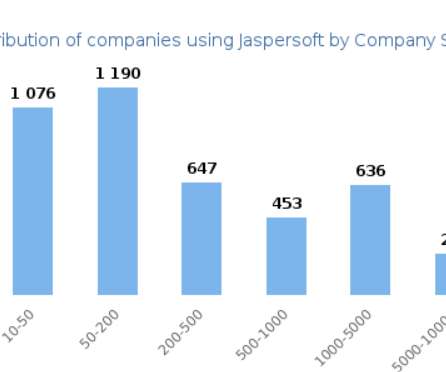
TIBCO Jaspersoft offers a complete BI suite that includes reporting, onlineanalyticalprocessing (OLAP), visual analytics , and data integration. The web-scale platform enables users to share interactive dashboards and data from a single page with individuals across the enterprise. Source: [link] ].
OnlineAnalyticalProcessing (OLAP) is crucial in modern data-driven apps, acting as an abstraction layer connecting raw data to users for efficient analysis. It organizes data into user-friendly structures, aligning with shared business definitions, ensuring users can analyze data with ease despite changes.
The data warehouse is highly business critical with minimal allowable downtime. Identify all upstream and downstream applications, as well as business processes that rely on the data warehouse. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources.
Amazon Redshift is a recommended service for onlineanalyticalprocessing (OLAP) workloads such as cloud data warehouses, data marts, and other analyticaldata stores. As the number of campaigns grew, Aura’s Data team was required to run hundreds of concurrent queries for each of these steps.
Data warehouse vs. databases Traditional vs. Cloud Explained Cloud data warehouses in your data stack A data-driven future powered by the cloud. We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. with a cloud data warehouse is simple.
Onlineanalyticalprocessing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. To build a robust OLAP system, it should provide accessibility regardless of location and data type.
Unfortunately, it also introduces a mountain of complexity into the reporting process. Most organizations are looking for sophisticated reporting and analytics, but they have little appetite for managing the highly complicated infrastructure that goes with it. This leads to the second option, which is a data warehouse.
StarTree can handle larger volumes of data efficiently with highly scalable implementations of minion tasks and a minion auto scaling feature that eliminates unnecessary infrastructure costs during idle times, as seen in the below figure. This post is cowritten with Mayank Shrivastava and Barkha Herman from StarTree.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content