This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. Introducing the next generation of SageMaker The rise of generative AI is changing how data and AI teams work together.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Reporting will change in D365 F&SCM, and those changes could significantly increase complexity and total cost of ownership. To enhance security, Microsoft has decided to restrict that kind of direct database access in D365 F&SCM and replace it with an abstraction layer comprised of something called “data entities”.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Consultants and developers familiar with the AX data model could query the database using any number of different tools, including a myriad of different report writers. The SQL query language used to extract data for reporting could also potentially be used to insert, update, or delete records from the database.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as business intelligence, data engineering, and machinelearning thus limiting the tools and capabilities that can be used. 5 seconds $0.08 8 seconds $0.07
Two years ago we wrote a research report about Federated Learning. We’re pleased to make the report available to everyone, for free. You can read it online here: Federated Learning. Federated Learning is a paradigm in which machinelearning models are trained on decentralized data.
Machinelearning is rewriting the rules of the gaming industry. One report showed that Caesars is investing $1 billion in big data. I still remember playing my favorite games growing up, before machinelearning was a thing or big data was a household word. Other companies are following suit.
Artificial Intelligence and machinelearning are the future of every industry, especially data and analytics. Let’s talk about AI and machinelearning (ML). AI and ML are the only ways to derive value from massive datalakes, cloud-native data warehouses, and other huge stores of information.
You can secure and centrally manage your data in the lakehouse by defining fine-grained permissions with Lake Formation that are consistently applied across all analytics and machinelearning(ML) tools and engines. Alice is excited about this decision as she can now build daily reports using her expertise with Athena.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. Easy to report problems and receive updates on fixes.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machinelearning (ML) applications.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
Fragmented systems, inconsistent definitions, outdated architecture and manual processes contribute to a silent erosion of trust in data. When financial data is inconsistent, reporting becomes unreliable. A compliance report is rejected because timestamps dont match across systems. Assign domain data stewards.
One-quarter (27%) of participants in our DataLake Dynamic Insights Research reported they were currently using data virtualization, and another two-quarters (46%) planned to include data virtualization in the future.
Gartner® recognized Cloudera in three recent reports – Magic Quadrant for Cloud Database Management Systems (DBMS), Critical Capabilities for Cloud Database Management Systems for Analytical Use Cases and Critical Capabilities for Cloud Database Management Systems for Operational Use Cases. Download the reports to see the detailed scores .
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources. The default output is log based.
Analytics is the means for discovering those insights, and doing it well requires the right tools for ingesting and preparing data, enriching and tagging it, building and sharing reports, and managing and protecting your data and insights. Azure DataLake Analytics.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machinelearning (ML) models to extract insights from data.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. Enable the Cost and Usage Reports. Run queries in Athena.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
This cloud service was a significant leap from the traditional data warehousing solutions, which were expensive, not elastic, and required significant expertise to tune and operate. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
Wolverine, which Slater says relies on SAP and Microsoft for its core infrastructure, is now “well along the journey in supply chain data” using SAP SAC analytics but has yet to embark on other aspects of its digital transformation, such as building a datalake and embracing AI, she says. We are not currently doing that.”.
They also built an Azure-based datalake to provide global visibility of the company’s data to its 13,000-strong workforce. Digital transformation projects have always been about creating a data-driven business. Previously, each Mosaic location operated its own digital infrastructure.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Predictive analytics tools blend artificial intelligence and business reporting. Composite AI mixes statistics and machinelearning; industry-specific solutions. Supports larger data management architecture; modular options available. What are predictive analytics tools? On premises or in SAP cloud. Per user, per month.
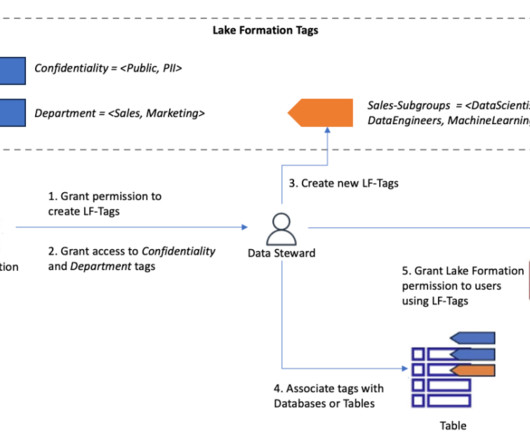
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
To derive value from this data, organizations must query the data regularly and share insights with relevant teams and departments. Some organizations have started using NLP in self-service analytics to quickly identify patterns and simplify data visualization.
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. These datasets are pivotal for reporting and analytics use cases, powered by services like Amazon Redshift and tools like Power BI.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
Nearly 95% of organizations say hybrid work has led them to invest more in data protection and security, according to NTT’s 2022–23 Global Network Report. You can use AI and machinelearning across security, networking and user experience management, all in the same datalake.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP Data Warehouse: a kubernetes-based service that allows business analysts to deploy data warehouses with secure, self-service access to enterprise data. Learn More, Keep in Touch. This is Now.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
Its data specialists use Snowflake to craft the architecture and capture a range of data types, from MLS listings to financial transactions, as well as national housing reports and “exhaust data that spits off the consumer-facing website,” Ligon says. Data Management, Digital Transformation, MachineLearning
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content