This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. Delete the bucket.
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machinelearning services to streamline the user journey from data to insight.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machinelearning (ML), and data monetization.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as business intelligence, data engineering, and machinelearning thus limiting the tools and capabilities that can be used.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Machinelearning is rewriting the rules of the gaming industry. One report showed that Caesars is investing $1 billion in big data. I still remember playing my favorite games growing up, before machinelearning was a thing or big data was a household word. Other companies are following suit.
Organizations are increasingly using a multi-cloud strategy to run their production workloads. We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. For this post, we use the Shared Key authentication method.
There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes. There has been a lot of talk over the past year or two in the D365F&SCM world about “datalakes.” Traditional databases and data warehouses do not lend themselves to that task.
Option 3: Azure DataLakes. This leads us to Microsoft’s apparent long-term strategy for D365 F&SCM reporting: Azure DataLakes. Azure DataLakes are highly complex and designed with a different fundamental purpose in mind than financial and operational reporting. Azure DataLakes are complicated.
In our previous post Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg , we showed how to use Apache Iceberg in the context of strategy backtesting. Our analysis shows that Iceberg can accelerate query performance by up to 52%, reduce operational costs, and significantly improve data management at scale.
Decades-old apps designed to retain a limited amount of data due to storage costs at the time are also unlikely to integrate easily with AI tools, says Brian Klingbeil, chief strategy officer at managed services provider Ensono. The aim is to create integration pipelines that seamlessly connect different systems and data sources.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Artificial Intelligence and machinelearning are the future of every industry, especially data and analytics. Let’s talk about AI and machinelearning (ML). AI and ML are the only ways to derive value from massive datalakes, cloud-native data warehouses, and other huge stores of information.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
It continues to position its document database product as a developer data platform which is primarily used to support the development and deployment of net-new applications rather than as a direct replacement for relational databases. The recent launch of MongoDB 8.0
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. Newer methods can work with large amounts of data and are able to unearth latent interactions.
I aim to outline pragmatic strategies to elevate data quality into an enterprise-wide capability. However, even the most sophisticated models and platforms can be undone by a single point of failure: poor data quality. This challenge remains deceptively overlooked despite its profound impact on strategy and execution.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. Data integrity presented a major challenge for the team, as there were many instances of duplicate data.
Real-time AI involves processing data for making decisions within a given time frame. Real-time AI brings together streaming data and machinelearning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. It isn’t easy.
That’s why Rocket Mortgage has been a vigorous implementor of machinelearning and AI technologies — and why CIO Brian Woodring emphasizes a “human in the loop” AI strategy that will not be pinned down to any one generative AI model. It’s a powerful strategy.” The rest are on premises.
The company recently migrated to Cloudera Data Platform (CDP ) and CDP MachineLearning to power a number of solutions that have increased operational efficiency, enabled new revenue streams and improved risk management. OCBC also won a Cloudera Data Impact Award 2022 in the Transformation category for the project.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Subsequently, we’ll explore strategies for overcoming these challenges.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machinelearning (ML) models to extract insights from data.
Taking the broadest possible interpretation of data analytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure DataLake Analytics. Microsoft. Azure Analysis Services.
This cloud service was a significant leap from the traditional data warehousing solutions, which were expensive, not elastic, and required significant expertise to tune and operate. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
This post explores how the shift to a data product mindset is being implemented, the challenges faced, and the early wins that are shaping the future of data management in the Institutional Division. Amazon DataZone plays an essential role in facilitating data product management for the domain teams.
It is important to note that data analytics relies on computer tools and software to collect and analyze data so that business choices may be made properly. Data analytics is widely used in business since it allows organizations to better understand their consumers and improve their advertising strategies.
As part of that transformation, Agusti has plans to integrate a datalake into the company’s data architecture and expects two AI proofs of concept (POCs) to be ready to move into production within the quarter. Like many CIOs, Carhartt’s top digital leader is aware that data is the key to making advanced technologies work.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with data quality, and lack of cross-functional governance structure for customer data.
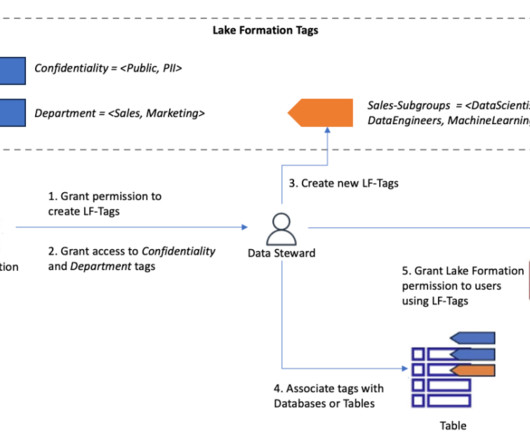
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
This integration empowers organizations to break down data silos, accelerate analytics, and drive more agile customer-centric strategies. In his current role at Salesforce, Sriram works on Zero Copy integration with major datalake partners and helps customers deliver value with their datastrategies.
Chipotle IT’s secret sauce Garner credits Chipotle’s wholly owned business model for enabling him to deploy advanced technologies such as the cloud, analytics, datalake, and AI uniformly to all restaurants because they are all based on the same digital backbone. Chipotle’s digital business in 2022 was $3.5
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content