This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). This led to inefficiencies in data governance and access control.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. Amazon Athena is used to query, and explore the data.
When Bob McCowan was promoted to CIO at Regeneron Pharmaceuticals in 2018, he had previously run the data center infrastructure for the $81.5 billion company’s scientific, commercial, and manufacturing businesses since joining the company in 2014. Much of Regeneron’s data, of course, is confidential.
Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein. The brand name may be more familiar as a streaming video device manufacturer, but Roku also places ads.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Monitoring Job Metadata.
Organizations are increasingly building low-latency, data-driven applications, automations, and intelligence from real-time data streams. Cloudera Stream Processing (CSP) enables customers to turn streams into data products by providing capabilities to analyze streaming data for complex patterns and gain actionable intel.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. sql_path SQL file name.
DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein. Roku OneView The brand name may be more familiar as a streaming video device manufacturer, but Roku also places ads.
You can find similar use cases in other industries such as retail, car manufacturing, energy, and the financial industry. In this post, we discuss why data streaming is a crucial component of generative AI applications due to its real-time nature.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.) But the implementation of AI is only one piece of the puzzle.
Use cases could include but are not limited to: workload analysis and replication, migrating or bursting to cloud, data warehouse optimization, and more. Should you find yourself looking for inspiration for your entry, we encourage you to have a look at the incredible work of last year’s data superheroes.
Even for more straightforward ESG information, such as kilowatt-hours of energy consumed, ESG reporting requirements call for not just the data, but the metadata, including “the dates over which the data was collected and the data quality,” says Fridrich. “The complexity is at a much higher level.”
In parallel, the Pinot controller tracks the metadata of the cluster and performs actions required to keep the cluster in an ideal state. Its primary function is to orchestrate cluster resources as well as manage connections between resources within the cluster and data sources outside of it.
Inability to maintain context – This is the worst of them all because every time a data set or workload is re-used, you must recreate its context including security, metadata, and governance. Alternatively, you can also spin up a different compute cluster and access the data by using CDP’s Shared Data Experience.
Prinkan: Yeah, one of them, I think, which we are currently working on is with a global electronics manufacturing company, where they are trying to implement a customer 360 platform to enable purpose-based search or recommendations, more than a feature basis. Pavan: Really fascinating discussion, Prinkan.
The solution to this massive data challenge embedded the Aspire Content Processing Framework into the Cloudera Enterprise Data Hub as a Cloudera Parcel – a binary distribution format containing the program files, along with additional metadata used by Cloudera Manager.
Aside from the Internet of Things, which of the following software areas will experience the most change in 2016 – big data solutions, analytics, security, customer success/experience, sales & marketing approach or something else? 2016 will be the year of the datalake. Is Netflix considered a software company these days?
In the back office and manufacturing, organizations invested in enterprise resource planning (ERP) software. Today, CDOs in a wide range of industries have a mechanism for empowering their organizations to leverage data. As data initiatives mature, the Alation data catalog is becoming central to an expanding set of use cases.
Rich metadata and semantic modeling continue to drive the matching of 50K training materials to specific curricula, leading new, data-driven, audience-based marketing efforts that demonstrate how the recommender service is achieving increased engagement and performance from over 2.3 million users.
As such banking, finance, insurance and media are good examples of information-based industries compared to manufacturing, retail, and so on. Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? Datalakes don’t offer this nor should they.
StarTrees automatic data ingestion framework is ideal for enterprise workloads because it improves scalability and reduces the data maintenance complexity often found in open source Pinot deployments. The data is then modelled to help you organize and structure the data fetched from the selected data source into Pinot tables.
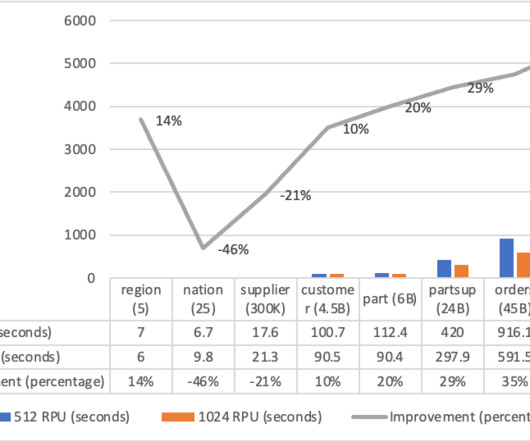
First, many data warehousing use cases involve processing petabyte-sized historical datasets, whether for initial data loading or periodic reprocessing and querying. This level of complex data processing requires substantial memory and parallel processing capabilities that can be effectively provided by a 1024 RPU configuration.
Amazon Data Firehose – Data Firehose is an extract, transform, and load (ETL) service that reliably captures, transforms, and delivers streaming data to datalakes, data stores, and analytics services. AWS Glue – The AWS Glue Data Catalog is your persistent technical metadata store in the AWS Cloud.
Customer data in Salesforce, product usage data in Snowflake and financials in Oracle none integrated Regional systems using different naming conventions and field formats This fragmentation leads to inconsistent definitions, duplication of work and multiple versions of the truth.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content