This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
To achieve this, they aimed to break down data silos and centralize data from various business units and countries into the BMW Cloud Data Hub (CDH). This led to inefficiencies in data governance and access control. For example, a global sales dataset is created by a team of data engineers with the data provider role.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
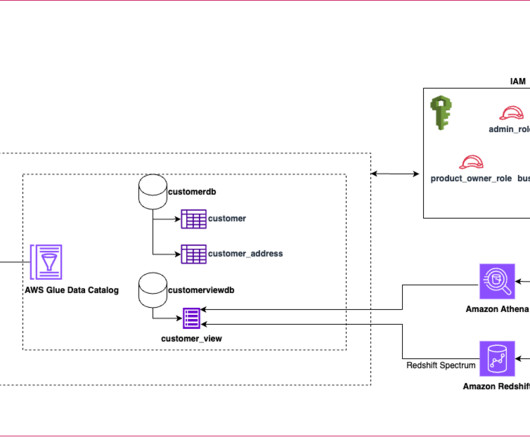
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and datalake. With Amazon Redshift, you can query the data in your S3 datalake using a central AWS Glue metastore from your Redshift data warehouse.
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
With improved access and collaboration, you’ll be able to create and securely share analytics and AI artifacts and bring data and AI products to market faster. This innovation drives an important change: you’ll no longer have to copy or move data between datalake and data warehouses.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? All the while, your marketing team is relying on marketing automation or CRM software they find the most productive.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern data architecture in separate AWS accounts.
These nodes can implement analytical platforms like datalake houses, data warehouses, or data marts, all united by producing data products. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. Amazon Athena is used to query, and explore the data.
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
But even with the “need for speed” to market, new applications must be modeled and documented for compliance, transparency and stakeholder literacy. With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis.
Lately, however, the term has been adopted by marketing teams, and many of the data management platforms vendors currently offer are tuned to their needs. In these instances, data feeds come largely from various advertising channels, and the reports they generate are designed to help marketers spend wisely.
These specific connectivity integrations are meant to allow healthcare providers to have a 360-degree view of all their important data and run analytics on them to take faster decisions and reduce time to market, Informatica said. Cloud Computing, Data Management, Financial Services Industry, Healthcare Industry
In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights. Connection to Amazon Redshift is established by deploying a data stream in Salesforce Data Cloud.
Then the data is consumed by SaaS-based computational tools, but it still sits within our organization and sits within the controls of our cloud-based solutions.” Much of Regeneron’s data, of course, is confidential. For that reason, many of its data tools — and even its datalake — were built in-house using AWS. “We
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publish data assets.
AWS-powered datalakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. It will never remove files that are still required by a non-expired snapshot.
Quick setup enables two default blueprints and creates the default environment profiles for the datalake and data warehouse default blueprints. The script creates a table with sample marketing and sales data. You will then publish the data assets from these data sources. AS wholesale_cost, 45.0
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
What’s changed since then, apart from Shih’s title, is Salesforce has rearchitected its underlying Data Cloud and Einstein AI framework to use an improved metadata framework, creating a new platform it calls Einstein 1. This means we now have a hyperscale data engine directly inside of Salesforce to connect all of your data,” he said.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
Deploying a DMP can be a great way for companies to navigate a business world dominated by data, and these platforms have become the lifeblood of digital marketing today. In these instances, data feeds come largely from advertising channels, and the reports they generate are designed to help marketers spend wisely.
When global technology company Lenovo started utilizing data analytics, they helped identify a new market niche for its gaming laptops, and powered remote diagnostics so their customers got the most from their servers and other devices. Without those templates, it’s hard to add such information after the fact.”
In this post, Morningstar’s DataLake Team Leads discuss how they utilized tag-based access control in their datalake with AWS Lake Formation and enabled similar controls in Amazon Redshift. This way, our existing datalake consumers could easily transition to Amazon Redshift.
Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600 ).
It provides personal and commercial banking, global markets, and investment banking services to 13 million customers. As they continue to implement their Digital First strategy for speed, scale and the elimination of complexity, they are always seeking ways to innovate, modernize and also streamline data access control in the Cloud.
Access audits are mastered centrally in Apache Ranger which provides comprehensive non-repudiable audit log for every access event to every resource with rich access event metadata such as: IP. Both fine-grained access control of database objects and access to metadata is provided. Sensitive data identification.
smava believes in and takes advantage of data-driven decisions in order to become the market leader. The Data Platform team is responsible for supporting data-driven decisions at smava by providing data products across all departments and branches of the company.
We are excited to announce a new feature in Amazon DataZone that allows data producers to group data assets into well-defined, self-contained packages (data products) tailored for specific business use cases. This eliminates the need for multiple permissions, speeding up the initiation of data analysis.
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation.
Amazon DataZone is a powerful data management service that empowers data engineers, data scientists, product managers, analysts, and business users to seamlessly catalog, discover, analyze, and govern data across organizational boundaries, AWS accounts, datalakes, and data warehouses.
To provide a variety of products, services, and solutions that are better suited to customers and society in each region, we have built business processes and systems that are optimized for each region and its market. Responsibilities include: Load raw data from the data source system at the appropriate frequency.
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
Our position as a Visionary in the Gartner Magic Quadrant for Cloud DBMS market speaks to our product excellence and market-leading-vision of a hybrid, multifunction integrated platform with built-in security and governance. . We were named a Visionary having a strong market understanding and a robust roadmap for the cloud DBMS market.
Developers, data scientists, and analysts can work across databases, data warehouses, and datalakes to build reporting and dashboarding applications, perform real-time analytics, share and collaborate on data, and even build and train machine learning (ML) models with Redshift Serverless. Choose Save changes.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
“By 2025, it’s estimated we’ll have 463 million terabytes of data created every day,” says Lisa Thee, data for good sector lead at Launch Consulting Group in Seattle. BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content