This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Table metadata is fetched from AWS Glue. The generated Athena SQL query is run.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
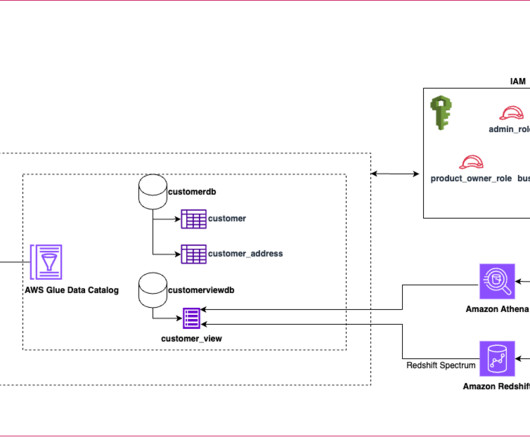
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. The AWS Glue Data Catalog holds the metadata for Amazon S3 and GCS data.
Cloudinary struggled to use this data for additional teams who had more online, real time, lower-granularity, dynamic usage requirements. Making petabytes of data accessible for ad-hoc reports became a challenge as query time increased and costs skyrocketed along with growing compute resource requirements.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. Introducing the next generation of SageMaker The rise of generative AI is changing how data and AI teams work together.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Alice is excited about this decision as she can now build daily reports using her expertise with Athena. Ava defines the user attributes as static IAM tags that could also include attributes stored in the identity provider (IdP) or as session tags dynamically to represent the user metadata. Set up a datalake admin.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. Easy to report problems and receive updates on fixes.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. For InitialRunFlag , choose Setup.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. Amazon Athena is used to query, and explore the data.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their data analytics capabilities to the scalable Amazon Redshift data warehouse. Amazon Redshift is a fully managed data warehouse service offered by Amazon Web Services (AWS).
Corporate ESG reporting is getting real for companies around the globe. Enacted and proposed regulations in the EU, US, and beyond are deepening reporting requirements in an effort to change business behavior. The foundation for ESG reporting, of course, is data. The foundation for ESG reporting, of course, is data.
In essence, a domain is an integrated data set and a set of views, reports, dashboards, and artifacts created from the data. The domain also includes code that acts upon the data, including tools, pipelines, and other artifacts that drive analytics execution.
These tools range from enterprise service bus (ESB) products, data integration tools; extract, transform and load (ETL) tools, procedural code, application program interfaces (APIs), file transfer protocol (FTP) processes, and even business intelligence (BI) reports that further aggregate and transform data.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
In our previous post Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 datalakes , we discussed how you can implement solutions to improve operational efficiencies of your Amazon Simple Storage Service (Amazon S3) datalake that is using the Apache Iceberg open table format and running on the Amazon EMR big data platform.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. EDLS job steps and metadata Every EDLS job comprises one or more job steps chained together and run in a predefined order orchestrated by the custom ETL framework.
Gartner® recognized Cloudera in three recent reports – Magic Quadrant for Cloud Database Management Systems (DBMS), Critical Capabilities for Cloud Database Management Systems for Analytical Use Cases and Critical Capabilities for Cloud Database Management Systems for Operational Use Cases. Download the reports to see the detailed scores .
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. Enable the Cost and Usage Reports. Run queries in Athena.
The delays impact delivery of the reports to senior management, who are responsible for making business decisions based on the dashboard. The automated orchestration published the data to an AWS S3 DataLake. I use the business rules I received from the business analyst to process the source data using Python.
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant datalake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
In an earlier blog, I defined a data catalog as “a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.”.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
“You had to be an expert in the programming language that interacts with that data, and understand the relationships of each data element within each data source, let alone understand its relation to elements in other data sources,” he says. Without those templates, it’s hard to add such information after the fact.”
To better understand and align data governance and enterprise architecture, let’s look at data at rest and data in motion and why they both have to be documented. Documenting data at rest involves looking at where data is stored, such as in databases, datalakes , data warehouses and flat files.
Elimination of data silos, consistency, accessibility, reliability, scalability, power of the cloud…. Snowflake is still exploding with data, and dealing with the ever-familiar issues like reporting errors, impact analysis, finding where PII is located and more can still cause your BI team to, well…. Cleaning up dirty data.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publish data assets.
Developers, data scientists, and analysts can work across databases, data warehouses, and datalakes to build reporting and dashboarding applications, perform real-time analytics, share and collaborate on data, and even build and train machine learning (ML) models with Redshift Serverless. Choose Activate.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content