This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
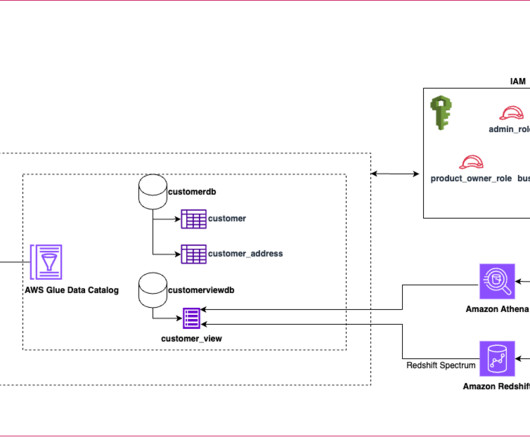
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machine learning (ML) models to extract insights from data.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging.
To support this need, ATPCO wants to derive insights around product performance by using three different data sources: Airline Ticketing data – 1 billion airline ticket salesdata processed through ATPCO ATPCO pricing data – 87% of worldwide airline offers are powered through ATPCO pricing data.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Quick setup enables two default blueprints and creates the default environment profiles for the datalake and data warehouse default blueprints. The script creates a table with sample marketing and salesdata. You will then publish the data assets from these data sources. AS wholesale_cost, 45.0
In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights. Connection to Amazon Redshift is established by deploying a data stream in Salesforce Data Cloud.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Monitoring Job Metadata. If that number ever decreases, something is wrong.
These business units have varying landscapes, where a datalake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publish data assets.
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
Having too much access across many departments, for example, can result in a kitchen full of inexperienced cooks running up costs and exposing the company to data security problems. And do you want your sales team making decisions based on whatever data it gets, and having the autonomy to mix and match to see what works best?
Amazon DataZone is a powerful data management service that empowers data engineers, data scientists, product managers, analysts, and business users to seamlessly catalog, discover, analyze, and govern data across organizational boundaries, AWS accounts, datalakes, and data warehouses.
What’s changed since then, apart from Shih’s title, is Salesforce has rearchitected its underlying Data Cloud and Einstein AI framework to use an improved metadata framework, creating a new platform it calls Einstein 1. Salesforce isn’t the first to come up with the idea of using generative AI to build a virtual coworker or copilot.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
These sources include ad marketplaces that dump statistics about audience engagement and click-through rates, sales software systems that report on customer purchases, and websites — and even storeroom floors — that track engagement. All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all.
For example, a marketing analysis data product can bundle various data assets such as marketing campaign data, pipeline data, and customer data. With the grouping capabilities of data products, data producers can manage and control access to the underlying data assets with just a few steps.
Introduction to OpenLineage compatible data lineage The need to capture data lineage consistently across various analytical services and combine them into a unified object model is key in uncovering insights from the lineage artifact. Now let’s harvest the lineage metadata using CloudShell. Choose Run.
This approach simplifies your data journey and helps you meet your security requirements. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. About the Authors Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team.
Inventory management benefits from historical data for analyzing sales patterns and optimizing stock levels. In fraud detection, historical data helps identify anomalous patterns in transactions or user behaviors. Hes passionate about helping customers use Apache Iceberg for their datalakes on AWS.
In this post, we demonstrate the following: Extracting non-transactional metadata from the top rows of a file and merging it with transactional data Combining multi-line rows into single-line rows Extracting unique identifiers from within strings or text Solution overview For this use case, imagine you’re a data analyst working at your organization.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Prior to this integration, you had to complete the following steps before Amazon DataZone could treat the published Data Catalog table as a managed asset: Identity the Amazon S3 location associated with Data Catalog table. Publish the table metadata to the Amazon DataZone business data catalog.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
The Data Platform team is responsible for supporting data-driven decisions at smava by providing data products across all departments and branches of the company. The departments include teams from engineering to sales and marketing. Branches range by products, namely B2C loans, B2B loans, and formerly also B2C mortgages.
The business end-users were given a tool to discover data assets produced within the mesh and seamlessly self-serve on their data sharing needs. The integration of Databricks Delta tables into Amazon DataZone is done using the AWS Glue Data Catalog. The following figure illustrates the data mesh architecture.
Every day, Amazon devices process and analyze billions of transactions from global shipping, inventory, capacity, supply, sales, marketing, producers, and customer service teams. This data is used in procuring devices’ inventory to meet Amazon customers’ demands. Then we chose Amazon Athena as our query service.
When Steve Pimblett joined The Very Group in October 2020 as chief data officer, reporting to the conglomerate’s CIO, his task was to help the enterprise uncover value in its rich data heritage. Understanding what data you’ve got locked in all these different stores is a big part of the jigsaw puzzle.”.
reduction in sales cycle duration, 22.8% Pillar 1: Data collection As you start building your customer data platform, you have to collect data from various systems and touchpoints, such as your sales systems, customer support, web and social media, and data marketplaces. Organizations using C360 achieved 43.9%
In a centralized architecture, data is copied from source systems into a datalake or data warehouse to create a single source of truth serving analytics use cases. This quickly becomes difficult to scale with data discovery and data version issues, schema evolution, tight coupling, and a lack of semantic metadata.
Data-driven decision making is the process of using facts, metrics, and data to guide strategic decisions that align with business goals. It empowers everyone — from business analysts and sales managers, to marketing specialists — to make better decisions about virtually any business challenge. Context aids understanding.
For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization. She also wants to predict future sales of both shoes and jewelry.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. We chatted about industry trends, why decentralization has become a hot topic in the data world, and how metadata drives many data-centric use cases.
Even for more straightforward ESG information, such as kilowatt-hours of energy consumed, ESG reporting requirements call for not just the data, but the metadata, including “the dates over which the data was collected and the data quality,” says Fridrich. “The complexity is at a much higher level.”
Other forms of governance address specific sets or domains of data including information governance (for unstructured data), metadata governance (for data documentation), and domain-specific data (master, customer, product, etc.). Data catalogs and spreadsheets are related in many ways. a spreadsheet.
Apache Hadoop Distributed File System (HDFS) is the most popular file system in the big data world. The Apache Hadoop File System interface has provided integration to many other popular storage systems like Apache Ozone, S3, Azure DataLake Storage etc. Migrating file systems thus requires a metadata update. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content