This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Today we are pleased to announce a new class of Amazon CloudWatch metrics reported with your pipelines built on top of AWS Glue for Apache Spark jobs. The new metrics provide aggregate and fine-grained insights into the health and operations of your job runs and the data being processed. workerUtilization showed 1.0
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. For example, for certain queries, Athena runtime was 2x–4x faster than Snowflake.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
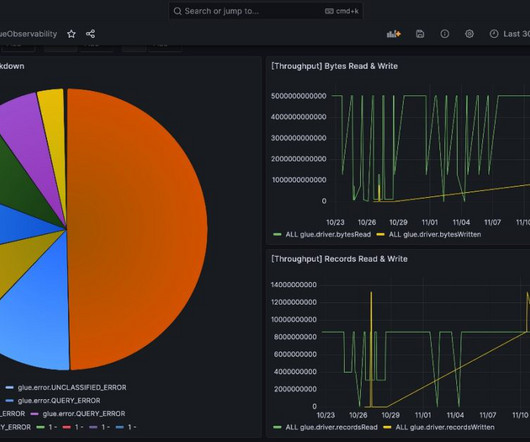
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your data integration pipelines built on AWS Glue. This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana. Choose Administration.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources. The default output is log based.
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Quality test suites will enforce “equity,” like any other performance metric. For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a datalake.
AI and ML are the only ways to derive value from massive datalakes, cloud-native data warehouses, and other huge stores of information. There just aren’t enough AI and data science practitioners to go around to tackle this lofty goal. Apply that metric to any other business-critical function.
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
We pulled these people together, and defined use cases we could all agree were the best to demonstrate our new data capability. Once they were identified, we had to determine we had the right data. Then we migrated the data to our new datalake, and stood up the new platform.
While this blog post helps you to get started using Amazon Redshift with Amazon S3 Tables, there are additional steps you need to consider when working with your data in production environments, including who has access to your data and with what level of permissions. impl=org.apache.iceberg.aws.s3.S3FileIO"
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
It shows the aggregate metrics of the files that have been processed by a auto-copy job. Eren Baydemir , a Technical Product Manager at AWS, has 15 years of experience in building customer-facing products and is currently focusing on datalake and file ingestion topics in the Amazon Redshift team.
AWS Glue Data Quality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug data quality issues. An AWS Glue crawler crawls the results.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. datazone_env_twinsimsilverdata"."cycle_end";') She can reached via LinkedIn. Siamak Nariman is a Senior Product Manager at AWS.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The gold model joins the technical logs with billing data and organizes the metrics per business unit.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. How to improve indexing.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
They also built an Azure-based datalake to provide global visibility of the company’s data to its 13,000-strong workforce. Digital transformation projects have always been about creating a data-driven business. For example, optimizing water usage in agriculture is a key metric.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. Measure user adoption and engagement metrics to not just understand products take-up, but also to enhance the overall product propositions.
Truly data-driven companies see significantly better business outcomes than those that aren’t. According to a recent IDC whitepaper , leaders saw on average two and a half times better results than other organizations in many business metrics. Most organizations don’t end up with datalakes, says Orlandini.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
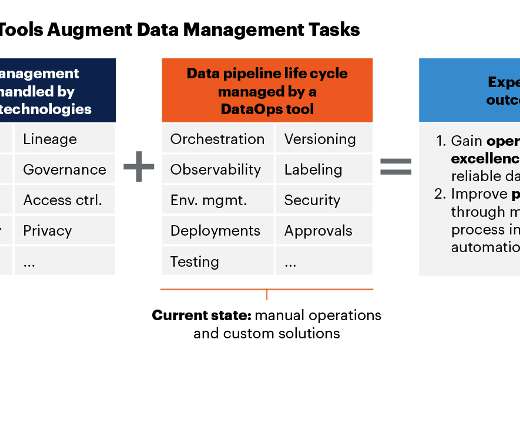
There’s a recent trend toward people creating datalake or data warehouse patterns and calling it data enablement or a data hub. DataOps expands upon this approach by focusing on the processes and workflows that create data enablement and business analytics. DataOps Process Hub.
The two things we are most excited about are: First, DataOps is distinct from all Data Analytic tools. As founders, we sat in a room eight years ago (when all the rage was Hadoop, data prep, and datalakes) and debated — will there ever be an ‘ops’ layer that sits next to all the current data tools?
Jon Pruitt, director of IT at Hartsfield-Jackson Atlanta International Airport, and his team crafted a visual business intelligence dashboard for a top executive in its Emergency Response Team to provide key metrics at a glance, including weather status, terminal occupancy, concessions operations, and parking capacity.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
Configure OpenSearch Service alerts to send notifications to PagerDuty We can monitor OpenSearch cluster health in two different ways: Using the OpenSearch Dashboard alerting plugin by setting up a per cluster metrics monitor. This provides a query to retrieve metrics related to the cluster health. Choose Preview query.
For its order-entry automation module, Northstar leans on AI and RPA to optimize data recognition and verification, and to reduce errors and accelerate order cycle times. The team also built a centralized datalake on AWS, Databricks, and Power BI. Catalyzing change.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. Amazon Redshift is built for scale and delivers up to 7.9
The Perilous State of Today’s Data Environments Data teams often navigate a labyrinth of chaos within their databases. Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Identifying Anomalies: Use advanced algorithms to detect anomalies in data patterns.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content