This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. This agility accelerates EUROGATEs insight generation, keeping decision-making aligned with current data. datazone_env_twinsimsilverdata"."cycle_end";')
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Refer to API Dimensions & Metrics for details.
By changing the cost structure of collecting data, it increased the volume of data stored in every organization. Additionally, Hadoop removed the requirement to model or structuredata when writing to a physical store. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structureddata from data warehouses. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
Stream processing, however, can enable the chatbot to access real-time data and adapt to changes in availability and price, providing the best guidance to the customer and enhancing the customer experience. When the model finds an anomaly or abnormal metric value, it should immediately produce an alert and notify the operator.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like datalakes.
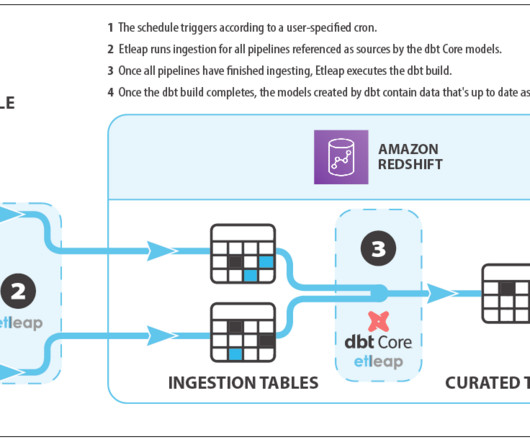
JSON data in Amazon Redshift Amazon Redshift enables storage, processing, and analytics on JSON data through the SUPER data type, PartiQL language, materialized views, and datalake queries. The function JSON_PARSE allows you to extract the binary data in the stream and convert it into the SUPER data type.
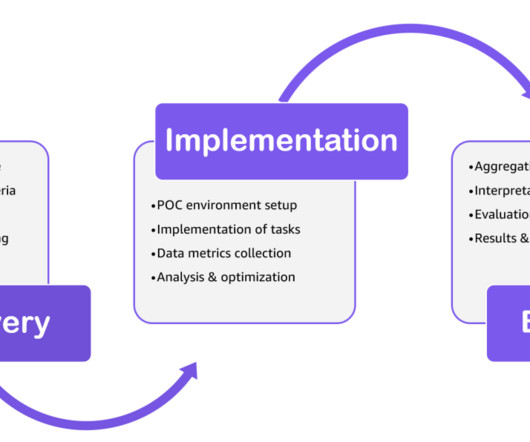
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Complete the implementation tasks such as data ingestion and performance testing.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.” ” Watsonx.ai
The following figure shows some of the metrics derived from the study. The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse.
Third-party APIs – These provide analytics and survey data related to ecommerce websites. This could include details like traffic metrics, user behavior, conversion rates, customer feedback, and more. Flat files – Other systems supply data in the form of flat files of different formats.
Building an optimal data system As data grows at an extraordinary rate, data proliferation across your data stores, data warehouse, and datalakes can become a challenge. This performance innovation allows Nasdaq to have a multi-use datalake between teams.
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021!
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structuredata for use, train machine learning models and develop artificial intelligence (AI) applications.
The success of the implementation meant assessing various aspects of the data infrastructure, data management, and business outcomes. They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers.
Once focused solely on reducing search and retrieval times, information lifecycle management (ILM) is now critical to workflow automation, identifying and tracking performance metrics, and harnessing the burgeoning potential of AI. Operationalizing data to drive revenue CIOs report that their roles are rising in importance and impact.
Historically restricted to the purview of data engineers, data quality information is essential for all user groups to see. Finally, data catalogs can help data scientists promulgate the results of their projects. Data scientists often have different requirements for a data catalog than data analysts.
Free Download of FineReport What is Business Intelligence Dashboard (BI Dashboard)? A business intelligence dashboard, also known as a BI dashboard, is a tool that presents important business metrics and data points in a visual and analytical format on a single screen.
Amazon Redshift helps you break down the data silos and allows you to run unified, self-service, real-time, and predictive analytics on all data across your operational databases, datalake, data warehouse, and third-party datasets with built-in governance.
For example, P&C insurance strives to understand its customers and households better through data, to provide better customer service and anticipate insurance needs, as well as accurately measure risks. Life insurance needs accurate data on consumer health, age and other metrics of risk.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Datalakes were originally designed to store large volumes of raw, unstructured, or semi-structureddata at a low cost, primarily serving big data and analytics use cases. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Mengchu currently works on query optimization and datalake query performance.
Leading-edge: Does it provide data quality or anomaly detection features to enrich metadata with quality metrics and insights, proactively identifying potential issues? Basic: Does the catalog recognize and register unstructured data sources, such as datalakes or document storage systems?
But what kind of data do you need for a solid use case? We used to need structureddata because our machine learning models expected field-level information. Today, we dont care if the data is structured because we can ingest it all, whether images, recordings, documents, PDF files, or large datalakes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content