This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. 1 from the same S3 bucket and prefix customer.
ML presents a problem for CI/CD for several reasons. The data that powers ML applications is as important as code, making version control difficult; outputs are probabilistic rather than deterministic, making testing difficult; training a model is processor intensive and time consuming, making rapid build/deploy cycles difficult.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
Will the datalake scale when you have twice as much data? Is your data secure? In this session, we address common pitfalls of building datalakes and show how AWS can help you manage data and analytics more efficiently. Javier Ramirez will present: The typical steps for building a datalake.
Datalakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Datalakes store all of an organization’s data, regardless of its format or structure.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. A data mesh framework empowers business units with data ownership and facilitates seamless sharing.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. Similarly, in a serverless paradigm, application logs in Amazon CloudWatch are sourced from a variety of participating services, and traversing the lineage across logs can also present challenges.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
In the current industry landscape, datalakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructured data. However, efficiently managing and synchronizing data within these lakespresents a significant challenge.
Solving the small file problem and improving query performance In modern data architectures, stream processing engines such as Amazon EMR are often used to ingest continuous streams of data into datalakes using Apache Iceberg. The following table shows the cost and time for each query and product. 5 seconds $0.08
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
Again, this entails creating a copy of the transactional data in the ERP system, but it also involves some preprocessing of data into so-called “cubes” so that you can retrieve aggregate totals and present them much faster. Unfortunately, Microsoft is not providing that kind of data warehouse solution out of the box.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
Organizations have chosen to build datalakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A datalake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Giving the mobile workforce access to this data via the cloud allows them to be productive from anywhere, fosters collaboration, and improves overall strategic decision-making. Connecting mainframe data to the cloud also has financial benefits as it leads to lower mainframe CPU costs by leveraging cloud computing for data transformations.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. In this post, we discuss the enhancement and present several use cases that the enhancement unlocks for your Amazon MWAA environment.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations.
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) datalakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems.
Klingbeil and Ensono have seen the challenges that legacy apps present for AI firsthand. This allows for the extraction and integration of data into AI models without overhauling entire platforms, Erolin says. CIOs should also use datalakes to aggregate information from multiple sources, he adds.
Enterprise data is brought into datalakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. Navigate to AWS CloudFormation. Choose Stacks. Select texttosqlmetadata Choose Delete.
Files already present at the S3 location will not be visible to the auto-copy job. Automate ingestion from a single data source With a auto-copy job, you can automate ingestion from a single data source by creating one job and specifying the path to the S3 objects that contain the data.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
These complex queries typically involve data sources from multiple business systems, requiring multilevel nested SQL or associations with numerous tables for highly sophisticated analytical tasks. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. In this physical plan, we don’t see the Exchange operation that is present in physical plan without storage partitioned join. Delta Lake highlights AWS Glue 5.0
In modern data architectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support.
Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
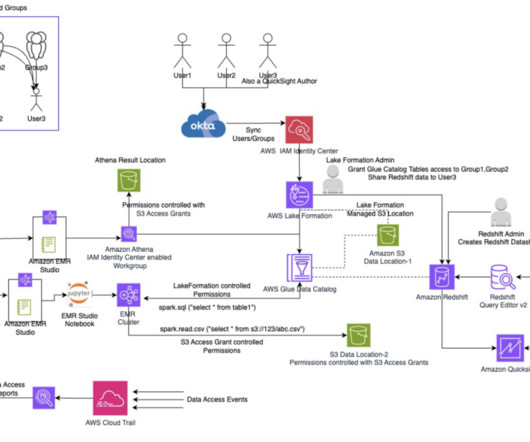
In this post, we showcase the seamless integration of AWS analytics services with trusted identity propagation by presenting an end-to-end architecture for data access flows. Provide a database name ( tip-blog-redshift-ds-db ), which will be created in the Data Catalog by Lake Formation.
present a significant barrier to adoption of the latest and greatest approaches. Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. In addition, the traditional challenges remain.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising data integrity. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code.
There’s a recent trend toward people creating datalake or data warehouse patterns and calling it data enablement or a data hub. DataOps expands upon this approach by focusing on the processes and workflows that create data enablement and business analytics. DataOps Process Hub.
Some of the more popular viral blogs and LinkedIn posts describe it as the following: A few observations on the modern stack diagram: Note the number of different boxes that are present. In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content