This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the context of comprehensive data governance, Amazon DataZone offers organization-wide data lineage visualization using Amazon Web Services (AWS) services, while dbt provides project-level lineage through model analysis and supports cross-project integration between datalakes and warehouses.
Delete and recreate your auto-copy job if you want to reset file tracking history and start over. Eren Baydemir , a Technical Product Manager at AWS, has 15 years of experience in building customer-facing products and is currently focusing on datalake and file ingestion topics in the Amazon Redshift team.
Además, el AC Milan está desarrollando un datalake compuesto por los datos médicos y de rendimiento de los jugadores con el mismo objetivo. “La La misión de nuestro equipo es apoyar al club y el negocio en todos los aspectos para lograr la excelencia dentro y fuera del terreno de juego.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
After launching industry-specific data lakehouses for the retail, financial services and healthcare sectors over the past three months, Databricks is releasing a solution targeting the media and the entertainment (M&E) sector. Features focus on media and entertainment firms.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Option 3: Azure DataLakes. This leads us to Microsoft’s apparent long-term strategy for D365 F&SCM reporting: Azure DataLakes. Azure DataLakes are highly complex and designed with a different fundamental purpose in mind than financial and operational reporting. Datalakes are not a mature technology.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. Data labeling is required for various use cases, including forecasting, computer vision, natural language processing, and speech recognition.
Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service. For instance, for a variety of reasons, in the short term, CDAOS are challenged with quantifying the benefits of analytics’ investments.
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.
For the last 30 years, whenever you want to do analytics, the first step is to rip it out of the operational applications and try and move it to a different environment—so data warehousing, datalakes, data lakehouses and now data clouds.
For the longest time, in order to do any analytics, we had to take the data to the technology — rip it out of the business applications and move it to a data warehouse or a datalake, or a data lakehouse. But now, thanks to the cloud and in-memory, we can bring the technology to the data.
Real-Time Intelligence, on the other hand, takes that further by supporting data in AWS, Google Cloud Platform, Kafka installations, and on-prem installations. “We We introduced the Real-Time Hub,” says Arun Ulagaratchagan, CVP, Azure Data at Microsoft. You can monitor and act on the data and you can set thresholds.”
Most innovation platforms make you rip the data out of your existing applications and move it to some another environment—a data warehouse, or datalake, or datalake house or data cloud—before you can do any innovation.
Despite nearly $1 billion in online revenue in 2020, the web-based outdoor recreational retailer was running its entire business on an outdated and unsupported e-commerce platform called ADT. Backcountry also lacked many core services critical for an online retailer — no CMS, no analytics, no data platform, and no datalake.
The next area is data. There’s a huge disruption around data. For a long time, we’ve always ripped data out of our core systems and put it into a data warehouse or a datalake or a datalake house or a data cloud. And then you have to recreate it all in this new area.
Advancements in analytics and AI as well as support for unstructured data in centralized datalakes are key benefits of doing business in the cloud, and Shutterstock is capitalizing on its cloud foundation, creating new revenue streams and business models using the cloud and datalakes as key components of its innovation platform.
Azure allows you to protect your enterprise data assets, using Azure Active Directory and setting up your virtual network. Other technologies, such as Azure Data Factory, can help process large amounts of data around in the cloud. The data is also distributed. So, Azure Databricks connects to many different data sources.
Storing data in a proprietary, single-workload solution also recreates dangerous data silos all over again, as it locks out other types of workloads over the same shared data. When your IT admin registers an environment in CDP, a DataLake is automatically deployed. Separate compute.
With SQLAlchemy we must specify that we wish to either append results (as in write more results to the bottom of the file) or overwrite results (as in drop the table and recreate). data = pd.read_csv('/mnt/data/modelOut.csv') data.to_sql('modelOutput', engine, index = False, if_exists='append'). About Domino Data Lab.
How Synapse works with DataLakes and Warehouses. Synapse services, datalakes, and data warehouses are often discussed together. Here’s how they correlate: Datalake: An information repository that can be stored in a variety of different ways, typically in a raw format like SQL.
Its acquisition of Topgolf International, completed in March 2021, added technology and tech-enabled entertainment to the mix, pushing the company toward digital transformation. Replatforming, data mining, building our datalakes to just clean the data, because back in those days it was so many systems, the data was not consistent.
Because of technology limitations, we have always had to start by ripping information from the business systems and moving it to a different platform—a data warehouse, datalake, data lakehouse, data cloud. It’s possible to do, but it takes huge amounts of time and effort to recreate all that from scratch.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
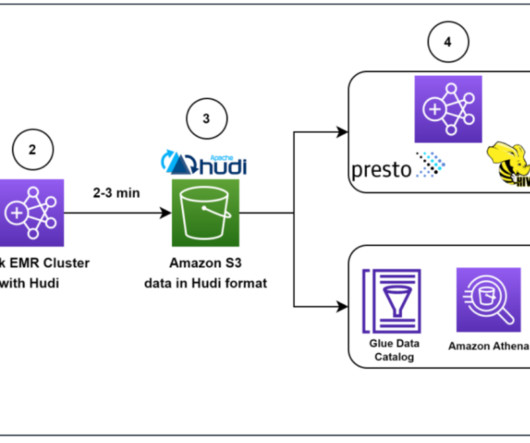
Apache Hudi provides a table format for datalakes with transactional semantics that enables the separation of ingestion workloads and updates when run concurrently. Overall, our approach to optimizing for low-latency reads with Apache Hudi allowed us to better manage file sizes and improve the overall performance of our datalake.
With real-time streaming data, organizations can reimagine what’s possible. From enabling predictive maintenance in manufacturing to delivering hyper-personalized content in the media and entertainment industry, and from real-time fraud detection in finance to precision agriculture in farming, the potential applications are vast.
In recent years, datalakes have become a mainstream architecture, and data quality validation is a critical factor to improve the reusability and consistency of the data. You can download the dataset or recreate it locally using the Python script provided in the repository.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
With effective collaboration, each contributor works toward a common goal: building off of the work of others and opening the door for more complete data governance. Without collaboration, the work of stewards is siloed and needlessly recreated. Guided Navigation Guided navigation helps data stewards locate sensitive data.
Let’s say new data sources are identified for your project, and as a result new attributes need to be introduced into your existing data model. Historically this could lead to long development cycles of recreating and reloading tables, especially if new partitions are introduced.
When a consumer requests table access from the central data catalog, the producer grants Lake Formation permissions to the consumer account AWS Identity and Access Management (IAM) role and tables are visible in the consumer account. The global catalog The basic building block of our business-focused solutions are data products.
In the case of CDP Public Cloud, this includes virtual networking constructs and the datalake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the data science workflow.
Inability to maintain context – This is the worst of them all because every time a data set or workload is re-used, you must recreate its context including security, metadata, and governance. Cloud deployments add tremendous overhead because you must reimplement security measures and then manage, audit, and control them.
The best way to avoid poor data quality is having a strict data governance system in place. The majority of the data a business has stored is generally unstructured. Most of these are accumulated in data silos or datalakes. Which means queries for large data sets might take days or eventually fail.
When we look at tools like Microsoft’s Power BI and Tableau, you must recreate complex data objects repeatedly across different teams and use cases. This is not conducive to ongoing and repeatable insights and value generation out of your data assets. This includes ETL processes and subsequent augmented and extended data sets.
Vision/Data Driven/Outcomes 28. Data, analytics, or D&A Strategy 21. Modern) Master Data Management 18. Datalake 4. Data Literacy 4. IoT/Streaming data 1. Platform questions: Data Management platform 15. Media & Entertainment 3. Organization, Rolls and Skills 8. AI/Automation 6.
Identify the Redshift data shares that were previously configured for the original producer cluster. Recreate these data shares on the new producer cluster in the target Region. Update the data share configurations in the consumer cluster to point to the newly created producer cluster.
Like the NFL, the NBA CTO opted to partner with Microsoft to leverage its Azure cloud platform, which Bhagavathula says contained all the digital components necessary to build the association’s streaming platform, while providing a cloud datalake and machine learning models the NBA could capitalize on for next-generation applications.
Plus, you can use other Amazon Redshift capabilities such as built-in machine learning, materialized views, data sharing, and federated access to multiple data stores and datalakes. You can see more other zero-ETL integrations use cases at What is ETL. Julia Beck is an Analytics Specialist Solutions Architect at AWS.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content