

Modernize your legacy databases with AWS data lakes, Part 3: Build a data lake processing layer
AWS Big Data
OCTOBER 30, 2024
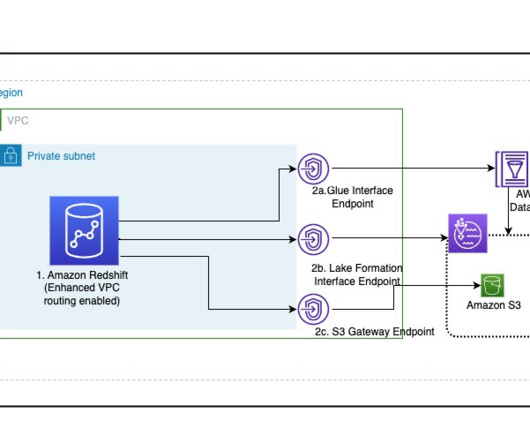
This is the final part of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. The following diagram illustrates the different layers of the data lake.

















































Let's personalize your content