This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
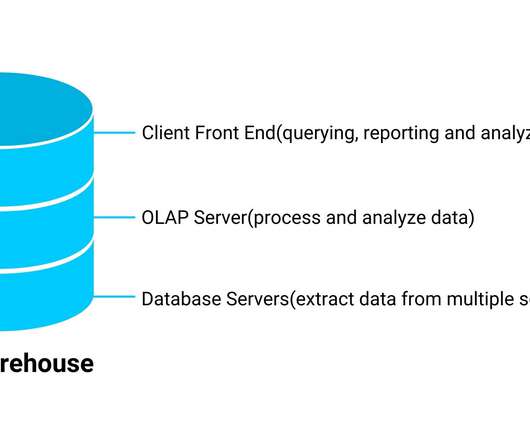
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
The company focused on delivering small increments of customer value data sets, reports, and other items as their guiding principle. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
Many organizations operate datalakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. Upload the data file to the S3 bucket created by the CloudFormation stack.
Data architectures to support reporting, business intelligence, and analytics have evolved dramatically over the past 10 years. Download this TDWI Checklist report to understand: How your organization can make this transition to a modernized data architecture. The decision making around this transition.
Reporting will change in D365 F&SCM, and those changes could significantly increase complexity and total cost of ownership. To enhance security, Microsoft has decided to restrict that kind of direct database access in D365 F&SCM and replace it with an abstraction layer comprised of something called “data entities”.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
Can data scientists discover and use the data? Can business people create reports via drag and drop? Will the datalake scale when you have twice as much data? Is your data secure? Javier Ramirez will present: The typical steps for building a datalake. A live demo of lake formation.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
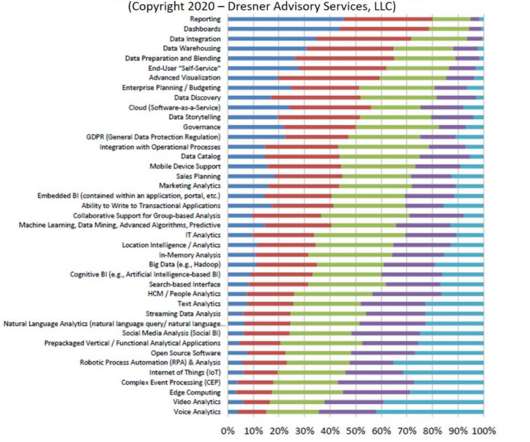
Dresner Advisory Services’ report about self-service business intelligence uncovered a surprising result. Among all the technologies and initiatives that respondents consider important, the item that topped the list was reporting. But seriously, reporting? How can you not think of "TPS Reports"? Let that sink in.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
Consultants and developers familiar with the AX data model could query the database using any number of different tools, including a myriad of different report writers. The SQL query language used to extract data for reporting could also potentially be used to insert, update, or delete records from the database.
Cloudinary struggled to use this data for additional teams who had more online, real time, lower-granularity, dynamic usage requirements. Making petabytes of data accessible for ad-hoc reports became a challenge as query time increased and costs skyrocketed along with growing compute resource requirements. 5 seconds $0.08
Our legacy architecture consisted of multiple standalone, on-prem data marts intended to integrate transactional data from roughly 30 electronic health record systems to deliver a reporting capability. But because of the infrastructure, employees spent hours on manual data analysis and spreadsheet jockeying.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. Introducing the next generation of SageMaker The rise of generative AI is changing how data and AI teams work together.
AI and ML are the only ways to derive value from massive datalakes, cloud-native data warehouses, and other huge stores of information. There just aren’t enough AI and data science practitioners to go around to tackle this lofty goal. Apply that metric to any other business-critical function.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
Corporate ESG reporting is getting real for companies around the globe. Enacted and proposed regulations in the EU, US, and beyond are deepening reporting requirements in an effort to change business behavior. The foundation for ESG reporting, of course, is data. The foundation for ESG reporting, of course, is data.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
One-quarter (27%) of participants in our DataLake Dynamic Insights Research reported they were currently using data virtualization, and another two-quarters (46%) planned to include data virtualization in the future.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. Easy to report problems and receive updates on fixes.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Download the Report. The Big Data revolution has been surprisingly rapid. Even five years ago many companies were still asking the question, “What is Big Data?”
Marketing invests heavily in multi-level campaigns, primarily driven by data analytics. This analytics function is so crucial to product success that the data team often reports directly into sales and marketing. As figure 2 summarizes, the data team ingests data from hundreds of internal and third-party sources.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. datazone_env_twinsimsilverdata"."cycle_end";') This led to a complex and slow computations.
Fragmented systems, inconsistent definitions, outdated architecture and manual processes contribute to a silent erosion of trust in data. When financial data is inconsistent, reporting becomes unreliable. A compliance report is rejected because timestamps dont match across systems. Assign domain data stewards.
Given the diverse data integration needs of customers, AWS offers a robust data integration system through multiple services including Amazon EMR , Amazon Athena , Amazon Managed Workflows for Apache Airflow (Amazon MWAA) , Amazon Managed Streaming for Apache Kafka (MSK) , Amazon Kinesis , and others.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. After assessment of the source SQL files, it generates a comprehensive report that provides valuable insights into the migration effort.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. Enable the Cost and Usage Reports. Run queries in Athena.
The investments you make in reporting and business intelligence tools today can provide added value to your current AX system and pave the way for a smoother, less expensive migration process down the road. Reporting Limitations of Dynamics AX. The existing Management Reporter in AX is a legacy tool that comes with limitations.
For example, teams working under the VP/Directors of Data Analytics may be tasked with accessing data, building databases, integrating data, and producing reports. Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
Gartner® recognized Cloudera in three recent reports – Magic Quadrant for Cloud Database Management Systems (DBMS), Critical Capabilities for Cloud Database Management Systems for Analytical Use Cases and Critical Capabilities for Cloud Database Management Systems for Operational Use Cases. Download the reports to see the detailed scores .
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. Discover the available data sources. Collaboratively develop reports. Automate as much as possible.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content