This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and datalakes and share some of Ventana Research’s findings on the subject.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate datalakes or warehouses—hinders visibility and cross-functional analysis. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
Unfortunately, data replication, transformation, and movement can result in longer time to insight, reduced efficiency, elevated costs, and increased security and compliance risk. Read this whitepaper to learn: Why organizations frequently end up with unnecessary data copies.
There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes. There has been a lot of talk over the past year or two in the D365F&SCM world about “datalakes.” Traditional databases and data warehouses do not lend themselves to that task.
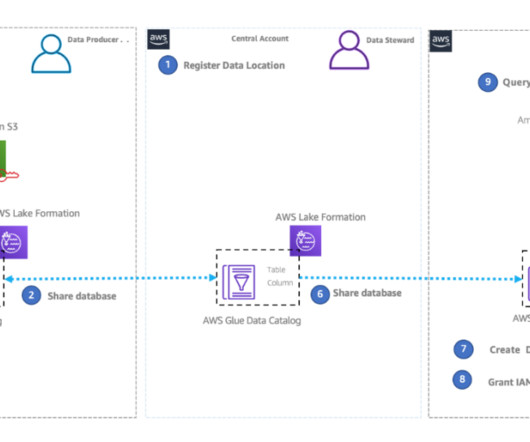
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
One key component that plays a central role in modern data architectures is the datalake, which allows organizations to store and analyze large amounts of data in a cost-effective manner and run advanced analytics and machine learning (ML) at scale. Why did Orca build a datalake?
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. The tools to transform your business are here.
The complexity and cost of SIEM solutions and the number of resources that security consumes can easily swallow a large portion of an enterprise’s budget, causing many organizations to fall behind in the security data race. Security datalakes can reduce organizations’ reliance on SIEM solutions.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Making your datalake a “governed datalake” is the game changer. Without governance, organizations risk securing the data and as well as protecting it. A governed datalake contains data that’s accessible, clean, trusted and protected.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale datalakes without requiring complex custom code. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites. At petabyte scale, Icebergs advantages become clear.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. That’s why many enterprises are adopting a two-pronged approach to GenAI.
Fragmented systems, inconsistent definitions, legacy infrastructure and manual workarounds introduce critical risks. Data quality is no longer a back-office concern. The decisions you make, the strategies you implement and the growth of your organizations are all at risk if data quality is not addressed urgently.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
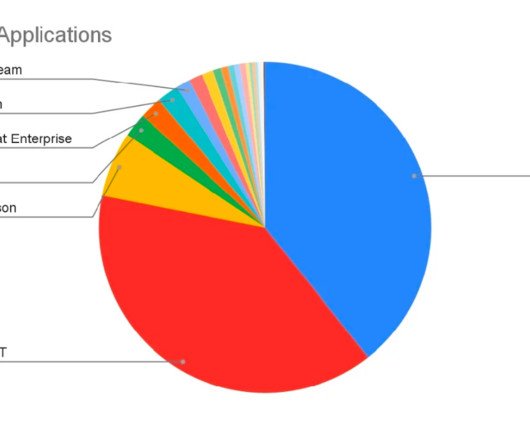
It will serve as the “nerve center” of an enterprise’s IT operation, the company said, adding that the offering will generate insights across an enterprise’s folio of applications to help reduce risk and compliance processes.
You can collect complete application ecosystem information; objectively identify connections/interfaces between applications, using data; provide accurate compliance assessments; and quickly identify security risks and other issues. You can better manage risk because of real-time data coming into the EA space.
Lack of clear, unified, and scaled data engineering expertise to enable the power of AI at enterprise scale. Regulations and compliance requirements, especially around pricing, risk selection, etc., Progressing AI based solutions from proof of concept or minimum viable product (MVP) to production.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits.
For NoSQL, datalakes, and datalake houses—data modeling of both structured and unstructured data is somewhat novel and thorny. This blog is an introduction to some advanced NoSQL and datalake database design techniques (while avoiding common pitfalls) is noteworthy. Data Modeling.
While sometimes at rest in databases, datalakes and data warehouses; a large percentage is federated and integrated across the enterprise, introducing governance, manageability and risk issues that must be managed. So being prepared means you can minimize your risk exposure and the damage to your reputation.
Preparing for an artificial intelligence (AI)-fueled future, one where we can enjoy the clear benefits the technology brings while also the mitigating risks, requires more than one article. This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. era is upon us.
The alternative to synthetic data is to manually anonymize and de-identify data sets, but this requires more time and effort and has a higher error rate. The European AI Act also talks about synthetic data, citing them as a possible measure to mitigate the risks associated with the use of personal data for training AI systems.
Doing it right requires thoughtful data collection, careful selection of a data platform that allows holistic and secure access to the data, and training and empowering employees to have a data-first mindset. Security and compliance risks also loom. Most organizations don’t end up with datalakes, says Orlandini.
While the potential of Generative AI in software development is exciting, there are still risks and guardrails that need to be considered. Risks of AI in software development Despite Generative AI’s ability to make developers more efficient, it is not error free. To learn more, visit us here. Artificial Intelligence, Machine Learning
Zscaler Enterprises will work to secure AI/ML applications to stay ahead of risk Our research also found that as enterprises adopt AI/ML tools, subsequent transactions undergo significant scrutiny. In all likelihood, we will see other industries take their lead to ensure that enterprises can minimize the risks associated with AI and ML tools.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
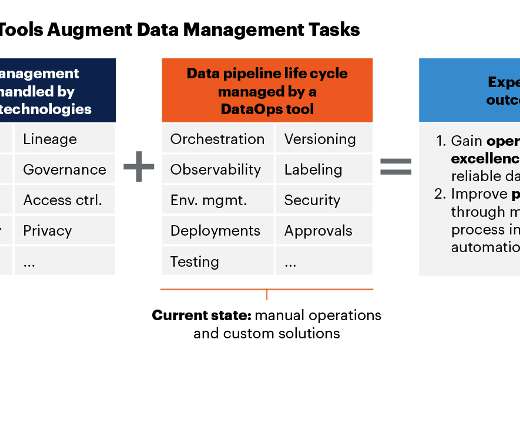
The two things we are most excited about are: First, DataOps is distinct from all Data Analytic tools. As founders, we sat in a room eight years ago (when all the rage was Hadoop, data prep, and datalakes) and debated — will there ever be an ‘ops’ layer that sits next to all the current data tools?
With Redshift, we are able to view risk counterparts and data in near real time— instead of on an hourly basis. Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications.
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the datalake and leverage various applications like ETL tools, search engines, and databases for analysis.
And you also already know siloed data is costly, as that means it will be much tougher to derive novel insights from all of your data by joining data sets. Of course you don’t want to re-create the risks and costs of data silos your organization has spent the last decade trying to eliminate. Must you be: .
No less daunting, your next step is to re-point or even re-platform your data movement processes. And you can’t risk false starts or delayed ROI that reduces the confidence of the business and taint this transformational initiative. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets.
Modern data architectures deliver key functionality in terms of flexibility and scalability of data management. This form of architecture can handle data in all forms—structured, semi-structured, unstructured—blending capabilities from data warehouses and datalakes into data lakehouses.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
We kept the data warehouse but augmented it with a cloud-based enterprise datalake and ML platform. The core customer data stays pristine in the data warehouse, but once the data goes into the lake, the business functions can experiment. The CIO’s new remit regarding business risk Now I’ve got it.
By leveraging the parallel compute capacity of GPUs the time for complicated data engineering and data science tasks can be dramatically reduced, accelerating the timeframes for Data Scientists to take ideas from concept to production. Data Ingestion. The raw data is in a series of CSV files.
In addition, data governance is required to comply with an increasingly complex regulatory environment with data privacy (such as GDPR and CCPA) and data residency regulations (such as in the EU, Russia, and China). Sharing data using LF-tags helps scale permissions and reduces the admin work for datalake builders.
Globally, financial institutions have been experiencing similar issues, prompting a widespread reassessment of traditional data management approaches. With this approach, each node in ANZ maintains its divisional alignment and adherence to datarisk and governance standards and policies to manage local data products and data assets.
With more companies increasingly migrating their data to the cloud to ensure availability and scalability, the risks associated with data management and protection also are growing. Data Security Starts with Data Governance. Lack of a solid data governance foundation increases the risk of data-security incidents.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content