This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a DataLake implemented with cloud storage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machine learning (ML) models to extract insights from data.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a business intelligence dashboard and take action on immediately.
The DataKitchen Platform ingests data into a datalake and runs Recipes to create a data warehouse leveraged by users and self-service data analysts. A sales or marketing team member could propose an idea –– what if we combined data from sources A and B to find potential customers for our new product?
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
In this example, we have multiple files that are being loaded on a daily basis containing the sales transactions across all the stores in the US. The following day, incremental sales transactions data are loaded to a new folder in the same S3 object path. The following screenshot shows sample data stored in files.
AI and ML are the only ways to derive value from massive datalakes, cloud-native data warehouses, and other huge stores of information. A recent Gartner report estimates that “by 2020, 50% of organizations will lack sufficient AI and data literacy skills to achieve business value.” That’s the state of AI.
First, make sure you’re connected to sample_data_dev Let’s ask the query “What are the top 10 stores in sales in 1998?” Amazon Q generative SQL is also personalized to your data domain. Our query runs successfully and shows that the store able has the most sales. So far, we have only been looking at store_sales data.
A solid ramp in initial interest puts a new medicine on a trajectory to meet its lifetime sales targets. During the product launch, everyone in the sales and marketing organizations is hyper-focused on business development. Marketing invests heavily in multi-level campaigns, primarily driven by data analytics.
With this platform, Salesforce seeks to help organizations apply the cleverness of LLMs to the customer data they have squirreled away in Salesforce datalakes in the hopes of selling more. Now with Einstein Studio 1, the AIs use your prompts to generate emails to any customer who might fit a sales profile.
In a data warehouse, a dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. To illustrate an example, in a typical sales domain, customer, time or product are dimensions and sales transactions is a fact.
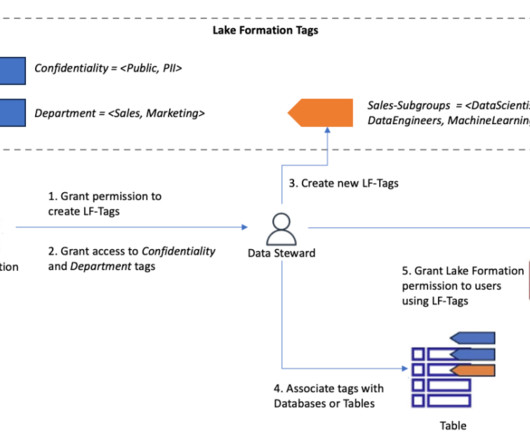
One of the core features of AWS Lake Formation is the delegation of permissions on a subset of resources such as databases, tables, and columns in AWS Glue Data Catalog to data stewards, empowering them make decisions regarding who should get access to their resources and helping you decentralize the permissions management of your datalakes.
The sales team at the consulting firm proposed that a bigger budget was needed to keep the data factory churning out enterprise-critical analytics. The data requirements of a thriving business are never complete. For example, DataOps can be used to automate data integration.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
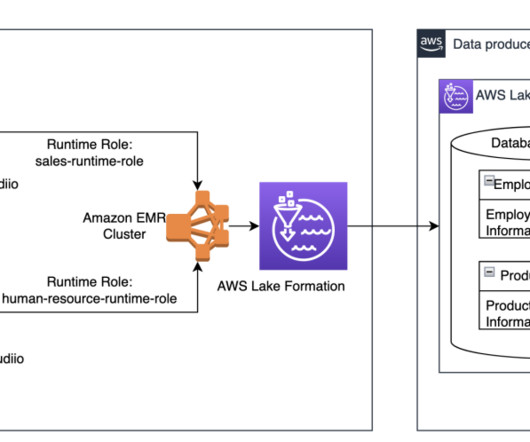
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
It manages large collections of files as tables, and it supports modern analytical datalake operations such as record-level insert, update, delete, and time travel queries. About the Authors Vivek Gautam is a Data Architect with specialization in datalakes at AWS Professional Services.
They also built an Azure-based datalake to provide global visibility of the company’s data to its 13,000-strong workforce. Deloitte Digital principal Nate Clark, who worked with Mosaic, emphasizes the end-to-end nature of the transformation, from supply chain to sales.
Fine-grained access control is a crucial aspect of data security for modern datalakes and data warehouses. As organizations handle vast amounts of data across multiple data sources, the need to manage sensitive information has become increasingly important.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. This pipeline reads data from different Amazon S3 based Data Catalog tables, performs transformations on the data, and writes the transformed data back into an Amazon S3.
To support this need, ATPCO wants to derive insights around product performance by using three different data sources: Airline Ticketing data – 1 billion airline ticket salesdata processed through ATPCO ATPCO pricing data – 87% of worldwide airline offers are powered through ATPCO pricing data.
In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights. Connection to Amazon Redshift is established by deploying a data stream in Salesforce Data Cloud.
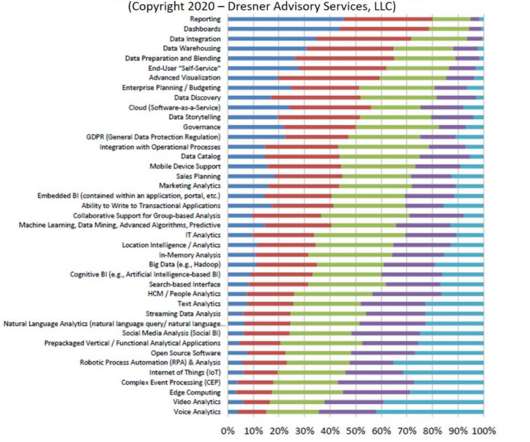
Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. But seriously, reporting? That has to be the most boring term in all of analytics. How can you not think of "TPS Reports"?
These business units have varying landscapes, where a datalake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
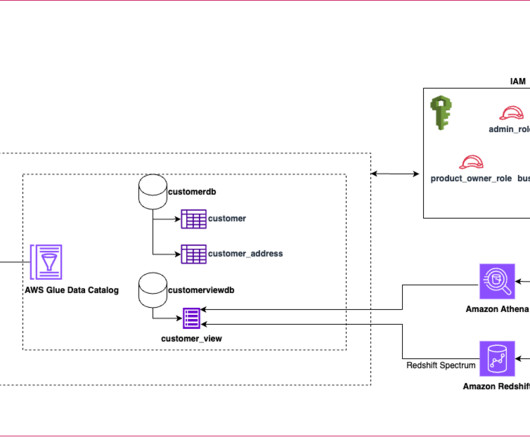
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose. Understand Your Audience.
You might be modernizing your data architecture using Amazon Redshift to enable access to your datalake and data in your data warehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. For IAM role , choose a Lake Formation user-defined role.
The rapid growth left the company highly dependent on fragmented, manual processes and disparate data sources and systems. For its order-entry automation module, Northstar leans on AI and RPA to optimize data recognition and verification, and to reduce errors and accelerate order cycle times. Catalyzing change.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
In today’s data economy, in which software and analytics have emerged as the key drivers of business, CEOs must rethink the silos and hierarchies that fueled the businesses of the past. They can no longer have “technology people” who work independently from “data people” who work independently from “sales” people or from “finance.”
Quick setup enables two default blueprints and creates the default environment profiles for the datalake and data warehouse default blueprints. The script creates a table with sample marketing and salesdata. You will then publish the data assets from these data sources. AS wholesale_cost, 45.0
Nonetheless, many of the same customers using DynamoDB would also like to be able to perform aggregations and ad hoc queries against their data to measure important KPIs that are pertinent to their business. Suppose we have a successful ecommerce application handling a high volume of sales transactions in DynamoDB.
These sources include ad marketplaces that dump statistics about audience engagement and click-through rates, sales software systems that report on customer purchases, and websites — and even storeroom floors — that track engagement. All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
From origin through all points of consumption both on-prem and in the cloud, all data flows need to be controlled in a simple, secure, universal, scalable, and cost-effective way. controlling distribution while also allowing the freedom and flexibility to deliver the data to different services is more critical than ever. .
Extras are priced by the sales team. Amazon’s main AI platform is well-integrated with the rest of the AWS fleet so you can analyze data from one of cloud vendor’s major data sources and then deploy it to run either in its own instance or as part of a serverless lambda function. Other combinations available from the sales team.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
As customer communication many times is verbal, transcribed data used by LLMs will revolutionize our order processing. In addition, textual data of restaurant menu cards, recipes will be interpreted using genAI tools to help us make our sales personnel extremely effective by being specific rather than vague.”
She further explains how the traditional BI systems which offers data visualization and building datalakes of structured and unstructured data, compliant with KPIs and analytics infrastructure may not be adequate to handle the data explosion. Monica holds a Master’s degree in Finance from Delhi University.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content