This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The biggest cons of the Tableau Public is that any data used in the program is ‘public’ and therefore not secure. And, with Tableau Public, published workbooks are “disconnected” from the underlying data sources and require periodic updates when the data changes. From Google. From Google.
The underlying data is in charge of data management, covering data collection, ETL, building a data warehouse, etc. The data analysis part is responsible for extracting data from the data warehouse, using the query, OLAP, datamining to analyze data, and forming the data conclusion with data visualization.
Then the reporting engine publishes these reports to the reporting portal to allow non-technical end-users access. In this way, users can gain insights from the data and make data-driven decisions. . The underlying data is responsible for data management, including data collection, ETL, building a data warehouse, etc.
The data warehouse is highly business critical with minimal allowable downtime. A loading team builds a producer-consumer architecture in Amazon Redshift to process concurrent near real-time publishing of data. This requires a dedicated team of 3–7 members building and publishing refined datasets in Amazon Redshift.
Users Want to Help Themselves Datamining is no longer confined to the research department. Today, every professional has the power to be a “data expert.” Quickly link all your data from Amazon Redshift, MongoDB, Hadoop, Snowflake, Apache Solr, Elasticsearch, Impala, and more. Standalone is a thing of the past.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

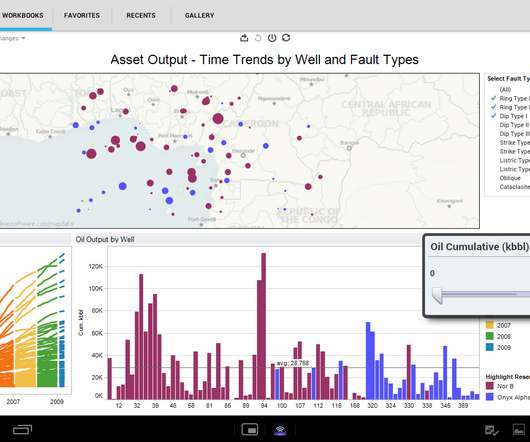
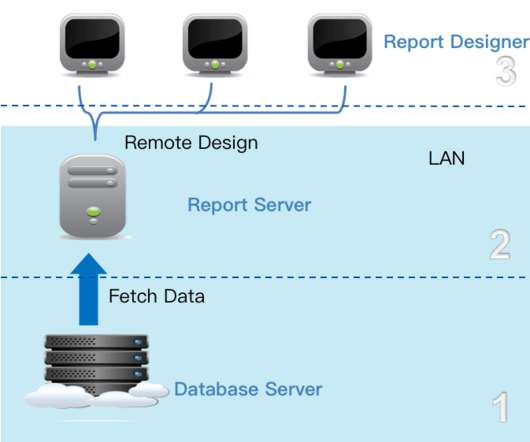
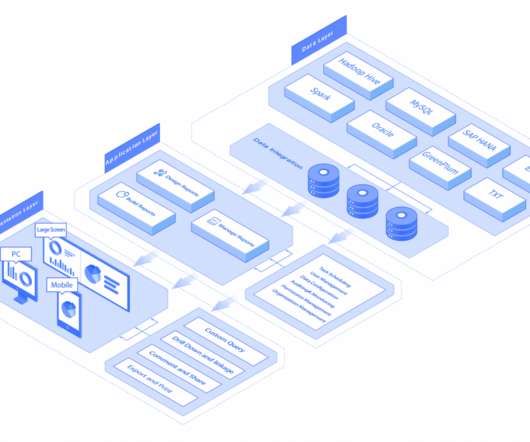










Let's personalize your content