This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
1) What Is Data Quality Management? 4) Data Quality Best Practices. 5) How Do You Measure Data Quality? 6) Data Quality Metrics Examples. 7) Data Quality Control: Use Case. 8) The Consequences Of Bad Data Quality. 9) 3 Sources Of Low-Quality Data. 10) Data Quality Solutions: Key Attributes.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
The need to integrate diverse data sources has grown exponentially, but there are several common challenges when integrating and analyzing data from multiple sources, services, and applications. First, you need to create and maintain independent connections to the same data source for different services.
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. Amazon Elastic Kubernetes Service (Amazon EKS) is becoming a popular choice among AWS customers to host long-running analytics and AI or machine learning (ML) workloads.
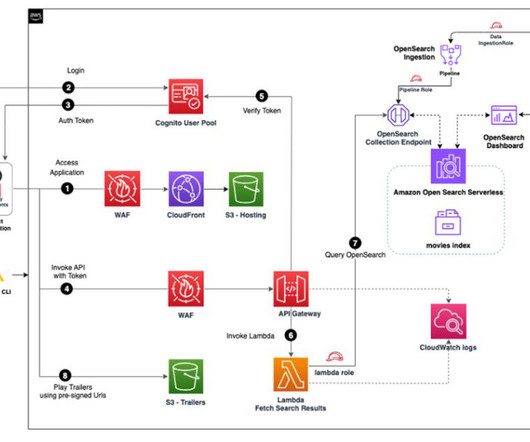
It allows organizations to secure data, perform searches, analyze logs, monitor applications in real time, and explore interactive log analytics. With its scalability, reliability, and ease of use, Amazon OpenSearch Service helps businesses optimize data-driven decisions and improve operational efficiency.
But there’s a host of new challenges when it comes to managing AI projects: more unknowns, non-deterministic outcomes, new infrastructures, new processes and new tools. AI products are automated systems that collect and learn from data to make user-facing decisions. Why AI software development is different.
Organizational data is often fragmented across multiple lines of business, leading to inconsistent and sometimes duplicate datasets. This fragmentation can delay decision-making and erode trust in available data. This solution enhances governance and simplifies access to unstructured data assets across the organization.
Data-driven insights are only as good as your data Imagine that each source of data in your organization—from spreadsheets to internet of things (IoT) sensor feeds—is a delegate set to attend a conference that will decide the future of your organization.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or data lakes cataloged with the AWS Glue data catalog.
With this new instance family, OpenSearch Service uses OpenSearch innovation and AWS technologies to reimagine how data is indexed and stored in the cloud. Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics.
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities.
Enterprises that need to share and access large amounts of data across multiple domains and services need to build a cloud infrastructure that scales as need changes. To achieve this, the different technical products within the company regularly need to move data across domains and services efficiently and reliably.
Organizations with a solid understanding of data governance (DG) are better equipped to keep pace with the speed of modern business. In this post, the erwin Experts address: What Is Data Governance? Why Is Data Governance Important? What Is Good Data Governance? What Are the Key Benefits of Data Governance?
Data governance is best defined as the strategic, ongoing and collaborative processes involved in managing data’s access, availability, usability, quality and security in line with established internal policies and relevant data regulations. Data Governance Is Business Transformation. Enhanced : Data managed equally.
This is evident in the rigorous training required for providers, the stringent safety protocols for life sciences professionals, and the stringent data and privacy requirements for healthcare analytics software. Concerns about data security, privacy, and accuracy have been at the forefront of these discussions.
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-drivendata queries, and more. In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
Advancement in big data technology has made the world of business even more competitive. The proper use of business intelligence and analytical data is what drives big brands in a competitive market. Business intelligence tools can include data warehousing, data visualizations, dashboards, and reporting.
Organizations are managing more data than ever. With more companies increasingly migrating their data to the cloud to ensure availability and scalability, the risks associated with data management and protection also are growing. Data Security Starts with Data Governance. Who is authorized to use it and how?
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
We use leading-edge analytics, data, and science to help clients make intelligent decisions. We developed and host several applications for our customers on Amazon Web Services (AWS). Data ingestion: The data ingestion layer is the first step of the proposed framework.
This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make data integration pipelines more efficient.
Co-chair Paco Nathan provides highlights of Rev 2 , a data science leaders summit. We held Rev 2 May 23-24 in NYC, as the place where “data science leaders and their teams come to learn from each other.” Nick Elprin, CEO and co-founder of Domino Data Lab. First item on our checklist: did Rev 2 address how to lead data teams?
We just announced Cloudera DataFlow for the Public Cloud (CDF-PC), the first cloud-native runtime for Apache NiFi data flows. Apache Nifi is a powerful tool to build data movement pipelines using a visual flow designer. Implementing an automated scale up and scale down procedure for NiFi clusters is complex and time consuming.
The company uses AWS Cloud services to build data-driven products and scale engineering best practices. To ensure a sustainable data platform amid growth and profitability phases, their tech teams adopted a decentralized data mesh architecture. The solution Acast implemented is a data mesh, architected on AWS.
In today’s data-driven world, organizations are continually confronted with the task of managing extensive volumes of data securely and efficiently. A common use case that we see amongst customers is to search and visualize data. A common use case that we see amongst customers is to search and visualize data.
INSITE applications are in general data intensive. They ingest and transform large volumes of data in different formats and processing patterns (such as batch and near real time) from various sources internal and external to Amazon. To enable and meet these requirements, GTTS built its own data platform.
What Makes a Data Fabric? Data Fabric’ has reached where ‘Cloud Computing’ and ‘Grid Computing’ once trod. Data Fabric hit the Gartner top ten in 2019. This multiplicity of data leads to the growth silos, which in turns increases the cost of integration. It is a buzzword.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. We think of this concept as inside-out data movement. Example Corp.
Data management platform definition A data management platform (DMP) is a suite of tools that helps organizations to collect and manage data from a wide array of first-, second-, and third-party sources and to create reports and build customer profiles as part of targeted personalization campaigns.
The foundation for ESG reporting, of course, is data. What companies need more than anything is good data for ESG reporting. That means ensuring ESG data is available, transparent, and actionable, says Ivneet Kaur, EVP and chief information technology officer at identity services provider Sterling.
Data teams have the impossible task of delivering everything (data and workloads) everywhere (on premise and in all clouds) all at once (with little to no latency). Each of these trends claim to be complete models for their data architectures to solve the “everything everywhere all at once” problem. Data mesh defined.
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. Data lakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams.
Swisscom’s Data, Analytics, and AI division is building a One Data Platform (ODP) solution that will enable every Swisscom employee, process, and product to benefit from the massive value of Swisscom’s data. The following high-level architecture diagram shows ODP with different layers of the modern data architecture.
Data and content are organized in a way that facilitates discoverability, insights and decision making rather than be bound by limitations of data formats and legacy systems. GraphQL has a number of advantages for developers, especially for data-centric applications. Content Enrichment and Metadata Management.
Apache Airflow is a popular platform for enterprises looking to orchestrate complex data pipelines and workflows. In this post, we’re excited to introduce two new features that address common customer challenges and unlock new possibilities for building robust, scalable, and flexible data orchestration solutions using Amazon MWAA.
Ever since Hippocrates founded his school of medicine in ancient Greece some 2,500 years ago, writes Hannah Fry in her book Hello World: Being Human in the Age of Algorithms , what has been fundamental to healthcare (as she calls it “the fight to keep us healthy”) was observation, experimentation and the analysis of data.
It enriched their understanding of the full spectrum of knowledge graph business applications and the technology partner ecosystem needed to turn data into a competitive advantage. Content and data management solutions based on knowledge graphs are becoming increasingly important across enterprises.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional data lake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. In this post, we discuss how you can use purpose-built AWS services to create an end-to-end data strategy for C360 to unify and govern customer data that address these challenges.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data. DATA FOR ENTERPRISE AI.
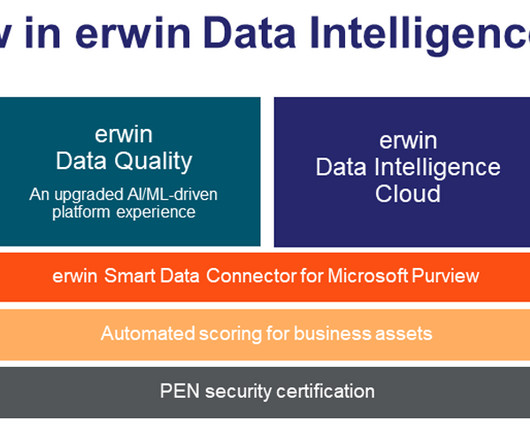
Added data quality capability ready for an AI era Data quality has never been more important than as we head into this next AI-focused era. erwin Data Quality is the data quality heart of erwin Data Intelligence. erwin Data Quality is the data quality heart of erwin Data Intelligence.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content